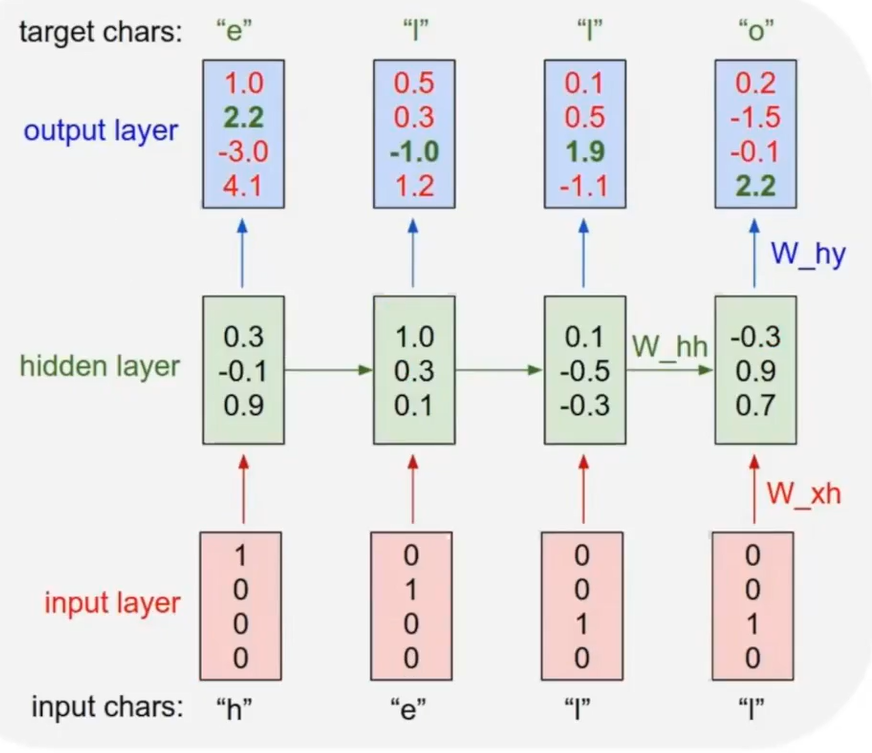
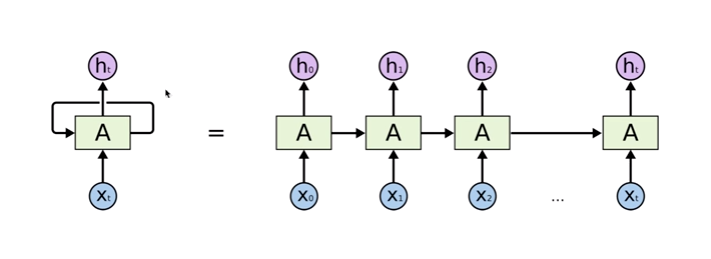
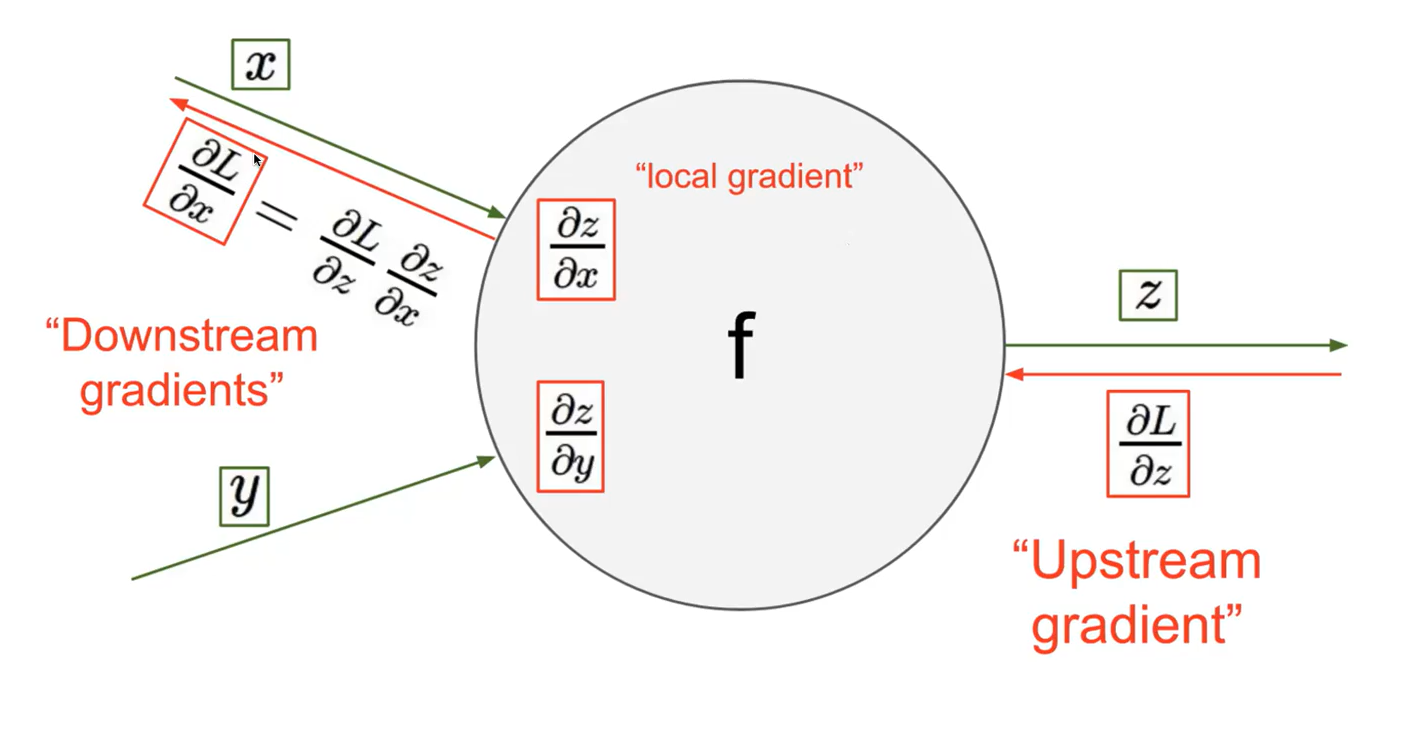
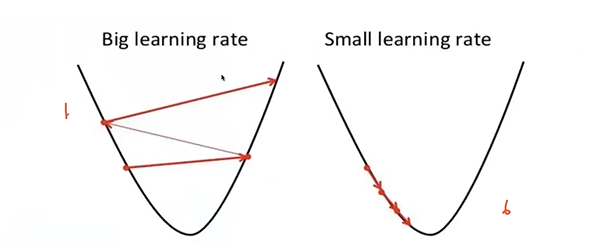
문제 1. Long-Term Dependencies Long-Term Dependencies : sequence data에서 이전 시간 단계의 정보가 현재 또는 미래 시간 단계에서의 예측에 영향을 미치는 경우를 말한다. Long term denpendesncies로 인하여 time 구간이 너무 길어서 가장 끝에 있는 loss function이 앞쪽에 있는 입력단까지 잘 전달이 되지 않을 수 있다. CNN에서 Layer가 깊어지면, update하는 과정에서 gradient가 잘 흘러가지 않는다. RNN도 마찬가지로 time step이 길어지면 출력값에 대해서 bptt를 통해 update되면서 gradient가 소실될 수 있다. h2에서의 loss function이 있다면, RNN에서는 그 이전 모든 영역에..