Temporal Modeling
[contents]
1. Recurrent Neural Networks (RNN)
2. Long Short-Term Memory (LSTM)
3. Transformer : Self-Attention
Recurrent Neural Networks (RNN)
Sequence Data
: RNN은 Sequence data를 처리하는 모델이다. Sequence data는 순서대로 처리되어야하는 data이며 음성인식, 자연어처리 등이 이에 포함된다. 자연어의 경우 단어 하나만 안다고해서 처리될 수 없고, 앞뒤 문맥을 함께 이해해야 해석이 가능하다. 따라서 지금까지 배운 neural network나 CNN만으로는 할 수 없다.

순차적으로 들어온느 입력을 그림으로 표현하면 위와 같다. 똑같은 구조가 무한하게 반복되는 것을 간단히 표현하기 위해 가장 왼쪽과 같은 형태로 표현하였다.
A에서 나온 화살표가 다시 A로 들어가는 해당 구조를 프로그래밍에서는 재진입(re-enterence) 또는 재귀(recursion)라고 부른다. 머신러닝 분야에서는 이러한 구조를 'recurrent' 직역하면 '다시 현재'라는 뜻으로 '되풀이'정도의 의미로 해석된다.
RNN에서 가장 중요한 것은 상태(state)를 갖는다는 것이다. 위 그림에서는 h가 상태를 의미한다.
Vanilla Neural Neworks
: 바닐라(vanilla)는 아무 것도 첨가하지 않은 처음 상태의 아이스크림을 의미한다. 여기에 초코나 딸기 시럽을 얹고 땅콩 가루를 뿌리는 등의 옵션을 추가하면 맛이 더 좋아진다. 바닐라는 아무 것도 가공하지 않은 처음 형태로, 바닐라 RNN은 가장 단순한 형태의 RNN 모델을 뜻한다

가장 왼쪽의 그림이 vanilla RNN이다. 가장 단순한 형태로 one-to-one 기반의 모델이다.
Image Captioning
: 이미지 캡션은 컴퓨터 비전과 자연어 처리를 결합한 작업으로, 주어진 이미지에 대한 설명(즉 캡션)을 자동으로 생성하는 것을 말한다. 이미지 캡션에는 하나의 input으로 여러개의 설명 output을 출력하는 one to many 기반의 모델이 사용된다.
rnn의 입력은 항상 x와 h가 같이 주어졌는데, one to many 인 경우 2번째 time step부터는 x로 무엇을 주어야할까.
대표적으로는 padding 처럼 의미가 없는 zero로 채워주는 것이 일반적이다. 경우에 따라서는 이전 time stpe의 y를 다음 time step의 input x으로 주는 경우도 있다.
Sentiment Classification (감정 분류)
: 직역하면 '감정 분류'라는 뜻으로, 주어진 텍스트의 문장이나 문서의 감정 상태를 분류하는 것을 말한다. 주로 긍정적, 부정적, 중립적 등과 같은 다양한 레이블 중 하나를 할당하는 것을 목표로 한다.
이는, 소셜 미디어 게시물,댓글 등에서 사용자의 의견 및 감정 추출 및 분석하기도 하며, 제품의 리뷰를 분석하여 제품 개선 또는 마케팅에 활용된다.
또는,비디오는 이미지가 연속적으로 조금씩 바뀌는 것이므로, sequence로 된 이미지 frame이 하나하나가 들어가서 video의 class를 분류하는 데에도 활요된다.
sentiment classification은 사용자나 고객의 의견들을 모아 긍정,부정과 같은 하나의 결과값으로 결론을 지어야하므로, 여러 입력에 대해 하나의 output을 출력하는 many to one 기법이 쓰인다.

Machine Translation (기계 번역)
: 한 언어에서 다른 언어로 번역하는 기술로, 인간 번역가 없이 기계가 언어를 번역하는 프로세스를 의미한다. 구글번역기나 파파고가 이에 해당한다.
1. 규칙 기반 기계 번역
: 언어간 문법 및 어휘 규칙을 기반으로 번역 수행.
2. 통계적 기계 번역
: 대량의 병렬 언어 코퍼스(원문과 번역본의 짝)에서 통계적으로 모델을 학습하여 번역 수행.
주어진 데이터에 의존적이므로, 충분한 양의 훈련 데이터가 필요함.
3. 신경망 기계 번역
: RNN이나 transformer를 사용하여 인코더와 디코더를 걸쳐 번역 수행.
machine translation은 다양한 단어와 문장들의 입력을 바탕으로 또 다른 언어로의 다양한 단어와 문장의 조합으로 표현해내야 하므로 many to many 기법이 사용된다.
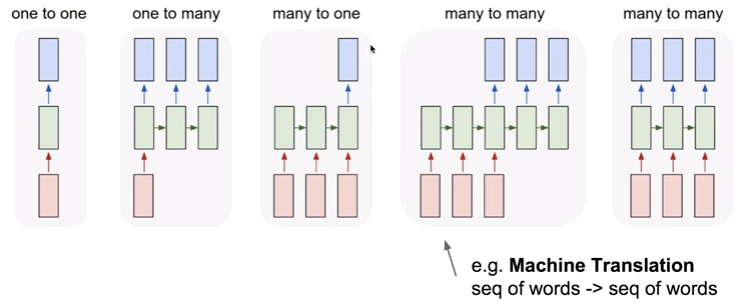

machine translation는 many to one 과 one to many 가 이어진 것이라 볼 수 있다.
many to one은 encoder로서 작동하고, one to many는 decoder로서 작동하며, 여러개의 input data를 하나의 hidden vector로 바꾸어주고, 그것을 다시 풀어낸다.
Video Classification on frame level
: 비디오 내의 각 프레임을 독립적으로 분석하고 해당 프레임이 어떤 카테고리에 속하는지를 예측하는 작업이다. 이 작업은 주로 컴퓨터 비전과 딥러닝 기술을 결합하여 수행된다.
비디오 프레임 수준에서의 비디오 분류는 주어진 비디오에서 각 프레임을 이미지로 추출한 후, 컨볼루션 신경망(CNN)과 같은 딥 러닝 모델을 사용하여 프레임을 카테고리 또는 클래스로 분류한다.
이 과정은 학습 단계에서 대량의 레이블이 지정된 비디오 데이터를 사용하여 모델을 훈련시키고, 추론 단계에서 새로운 비디오의 프레임을 모델에 입력하여 해당 비디오의 내용을 자동으로 분류하는 데 사용된다.
이러한 비디오 분류 작업은 비디오 검색, 콘텐츠 분류, 보안 감시, 스포츠 이벤트 인식 등 다양한 응용 분야에서 중요한 역할을 한다.
영상 프레임에 대해 class를 예측해야하므로 many to many 기법이 쓰인다.
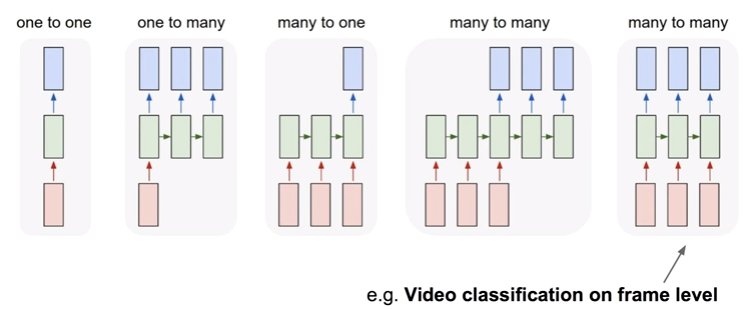
기계 번역과 video classification은 둘다 many to many 기법이 쓰이지만, 기계 번역은 대응 관계 학습이 필요하기 때문에 입력과 출력 사이 수행해야할 작업들이 video classification보다 많다.
Recurrent Neural Network

RNN은 크게 세 가지의 가중치를 포함한다.
1. input weights (Wxh)
: 현재 시간 단계의 입력과 연결된 가중치이다.
(x를 hidden state로 바꾸어주는 weight matrix이다.)
2. hidden state weights (Whh)
: 이전 시간 단계의 숨겨진 상태와 연결된 가중치이다.
(이전 time step 에서 현재 time step으로 넘어올 때 곱해주는 weight matirx로,
rnn을 selt update하는 과정에서 쓰인다.)
3. output weights
: 현재 시간 단계의 출력과 연결된 가중치이다.
RNN은 주로 순차적인 데이터나 시계열 데이터를 처리하기 위하여 설계되었기 때문에 시간개념으로 weights를 다룬다.
RNN은 현재 시간 단계의 입력을 처리하고, 이전 시간 단계의 숨겨진 상태를 사용하여 정보를 저장하고 전달하는 것이다. 이렇게 하면 RNN이 이전 단계에서의 정보를 현재 단계에서 사용할 수 있어 시간적 의존성을 파악할 수 있다. 예를 들면 문장을 생성하는 언어 모델에서는 이전(앞선) 단어의 의미가 현재 단어의 선택에 영향을 미칠 수 있다.
여기서 시계열 데이터란 일정 기간 간격으로 측정된 데이터 포인트의 시퀀스를 나타낸다. 일반적으로 일정 시간 간격으로 측정된 것으로, 시간에 따른 변화를 기록하거나 관찰한 데이터이다.시계열 데이터의 예로 금융 분석, 기상 예측 등을 들 수 있다.
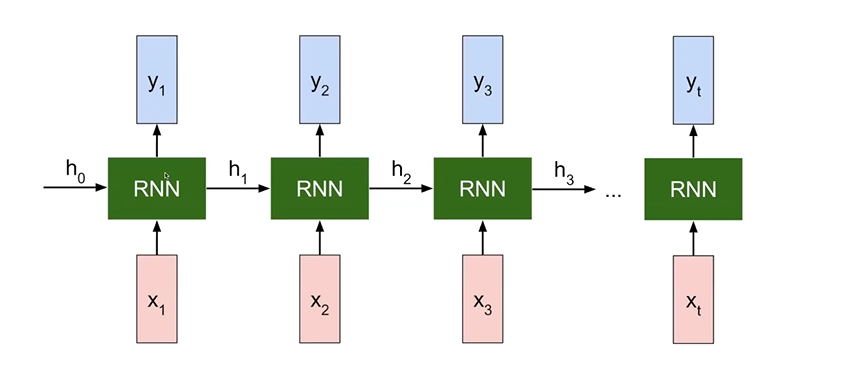
RNN을 펼쳐보면 위와 같다. 이전에는 현재의 입력에 대해서만 출력이 나왔다면, RNN은 이전의 featrue vector로부터 변환을 거쳐 들어오는 h series가 들어온다. 처음 h0는 random하게 bias 처럼 들어오고, x1까지 들어오면 state 즉 feature vector를 update 시키고, 두번 째 입력 x2를 넣을 때, 첫번째 입력으로부터 feature vector 로 바꾼 weight state가 같이 들어온다. 즉, 과거의 history를 현재의 것과 같이 받아서 update시키는 것이다.
기법마다 x와 y의 배치는 다를 수 있다. many to one의 경우 y1,y2..이렇게 줄줄이 있지 않을 것이다.즉 RNN이라는 것은 시간 데이트를 축적시키며 update시켜주는 h를 가지는 것이 포인트이다.

이를 수식으로 표현하면 다음과 같다. 시계열 데이터를 다룰 때에는 하단에 t라는 첨자가 항상 붙는다. 예를 들어 문장의 단어들을 다룰 때에는 t가 첫번째 단어,두번째 단어,... 와 같은 index를 의미하게 될 것이다.
feature vector 의 또 다른 명칭은 hidden state, hidden vector이다.
t번 째 시간 stpe에서의 state는 이전 hidden state와 현재 있는 t번째에서 입력이 관여되는 함수가 W가 된다.
(h는 RNN의 state를 의미)
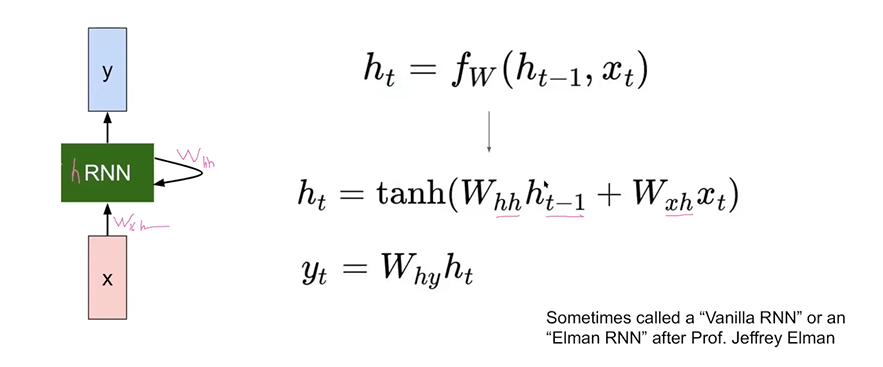
tanh는 non-linear로 만들어주기 위해 쓰인 것일 뿐이므로, 고정적이지 않으니 ReLU와 같은 다른 activation function으로 대체될 수 있다.
위 수식을 분석해보면 현재의 hidden state는 이전 시간의 hidden state와 현재 RNN의 hidden state weights를 곱한 것과 input weight와 x를 곱한 것의 합을 non-linear한 함수로 비선형화 시켜준 값이 현재 rnn의 hidden state값이 된다.
yt는 마지막 값이므로 output weight와 hidden state를 linear하게 곱해서 출력한다.
Computational Graph : Many to Many

hidden state를 계산하는 함수로서 작용하는 fw는 시간 step이 바뀌어도 변화가 없다. fw는 시간에 대한 dependency가 있는 것이 아니라 그냥 하나로 존재한다.

펼쳐놓은 것을 봤을 때 모든 것들에 대해서 어떤 길이의 input도 fw 하나를 가지고 학습시키기 때문에 모든 time에 대해서 fw가 historical하게 모든 time에 대해 기억을 하고있어야 한다.

many to many 기법의 경우 각 time의 마다의 output이 존재하는데 이로 loss function을 구할 수 있다. output이 여러개 존재하는 경우 loss function도 여러개 생기는데, 이 loss function들을 모두 더해서 평균치를 내어 하나의 loss function으로 표현할 수 있다.
또한 이러한 과정을 역추적하는 backpropagation을 RNN에서는 BPTT(backpropagation through time)라고 한다.
bptt는 RNN의 순전파 단계에서 발생한 오차를 역방향으로 시간에 따라 역전파하여 네트워크의 가중치를 조정한다.
RNN이 BPTT를 할 때는 그래디언트 소실을 주의해야한다. 역전파를 하며 모델의 weight를 update하기 위해 그래디언트를 사용하는데, 최신 상태의 것을 update하고 역전파 과정에서 그 이전의 것을 또 update하면 모델을 다시 순전파로 돌렸을 때, 그래디언트가 연속적으로 작아져서 사라져버리는 경우가 생긴다.