문제 1. Long-Term Dependencies
Long-Term Dependencies
: sequence data에서 이전 시간 단계의 정보가 현재 또는 미래 시간 단계에서의 예측에 영향을 미치는 경우를 말한다.
Long term denpendesncies로 인하여 time 구간이 너무 길어서 가장 끝에 있는 loss function이 앞쪽에 있는 입력단까지 잘 전달이 되지 않을 수 있다.

CNN에서 Layer가 깊어지면, update하는 과정에서 gradient가 잘 흘러가지 않는다.
RNN도 마찬가지로 time step이 길어지면 출력값에 대해서 bptt를 통해 update되면서 gradient가 소실될 수 있다.
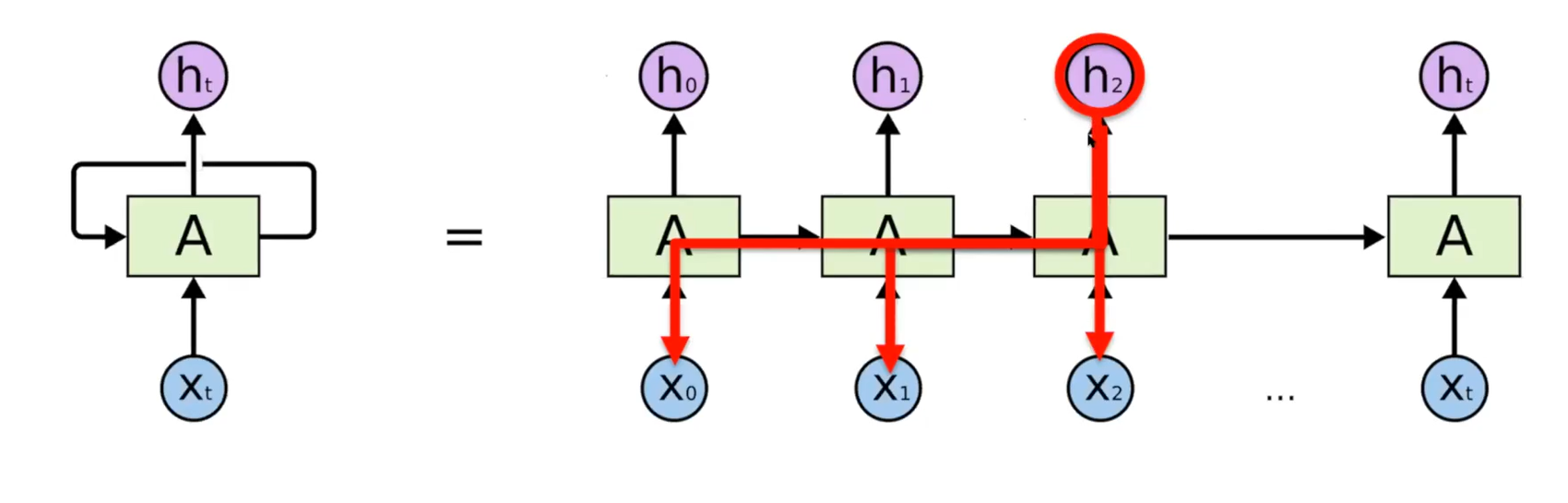
h2에서의 loss function이 있다면, RNN에서는 그 이전 모든 영역에 영향을 주게 될 것이다.
Model capacity
: : 모델이 주어진 작업을 수행하는 데 얼마나 많은 정보를 담을 수 있는지를 나타내는 것이다.
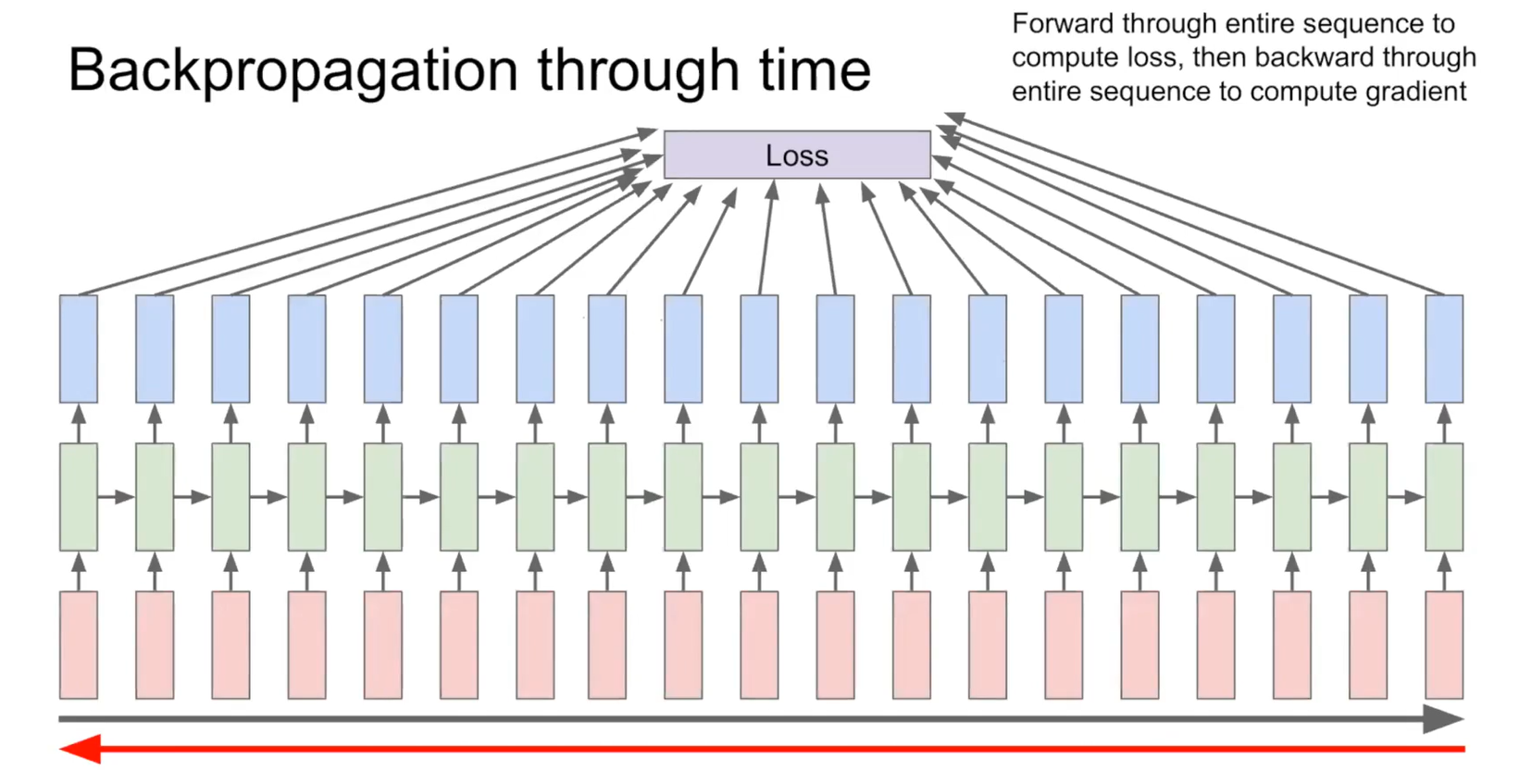
model이 수용할 수 있는 time step을 정해놔야 한다.
입력이 만약 model capacity보다 적게 들어오면 처음부터 채우다가 끝단 부분은 zero로 채운다. 그리고 만약, capacity가 부족하면 layer층을 추가하면 되지만 너무 deep하게 만들면 long-term dependencies가 생긴다.
Truncated Backpropagation through time
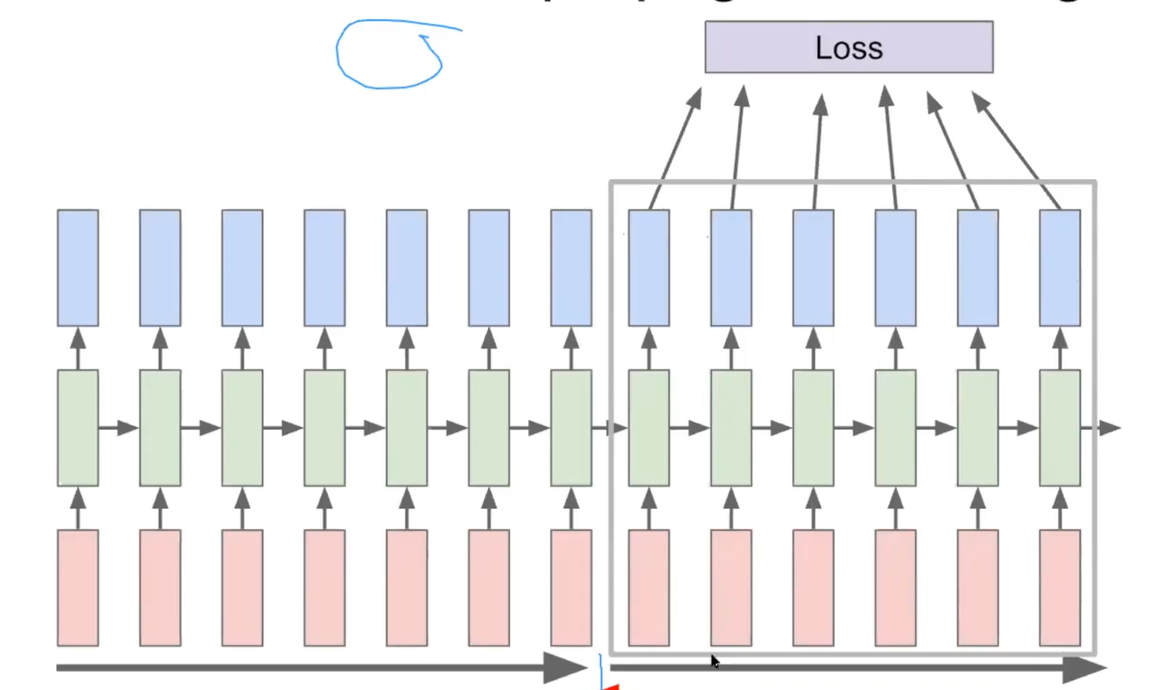
: layer를 막연하게 추가할 수 없으므로, 트렁케이티드 bptt 방법으 time step을 작게 줄여 input을 끊어서 준다.
많은 정보를 넣기 위해 layer만 추가하면 어차피 제대로 동작할 수 없으므로 주어진 model capacity에 맞추어 input을 여러번 끊어 넣는다. 이로써 dependencies를 해결해준다.
문제2. Gradient Flow of RNN

Gradient flow
- Largest singular value
: RNN에서 gradient가 RNN 셀의 weight matrix와 반복적으로 곱해지는 과정에서 계산된다.
- Exploding gradients ( Largest singular value > 1 ) //기울기 폭발
역전파 알고리즘이 순차 데이터의 각 시간 단계를 거슬러 올라가면서 기울기를 계산하고 가중치를 업데이트합니다. 이런 과정에서 gradient가 반복적으로 곱해질 수 있습니다.
Gradient Explosion은 다음과 같이 수식으로 나타낼 수 있습니다. 간단한 RNN 셀을 예로 들어봅시다: RNN의 출력(예: hidden state)을 H라고 합시다. 각 시간 단계 t에서의 역전파에서는 다음과 같은 과정이 진행됩니다: Loss L을 H로 미분하여 dL/dH를 계산합니다. dL/dH를 사용하여 가중치 U에 대한 gradient를 계산합니다. dL/dH를 사용하여 이전 시간 단계(t-1)의 hidden state H(t-1)에 대한 gradient도 계산합니다.
만약 gradient가 큰 값(1보다 큰 값)으로 시작하고 이 gradient가 반복적으로 곱해진다면, 시간 단계가 진행됨에 따라 gradient가 기하급수적으로 커질 수 있습니다. 이렇게 커진 gradient는 가중치 업데이트 시에 너무 큰 변화를 가져와서 모델의 파라미터가 수렴하지 않고 발산하게 됩니다.
Gradient Explosion 문제를 해결하기 위한 일반적인 방법 중 하나는 **기울기 클리핑(Gradient Clipping)**을 사용하는 것입니다. 기울기 클리핑은 gradient가 특정 임계값을 초과하지 않도록 제한하는 방법입니다.
이를 통해 gradient가 너무 커지는 것을 방지하고 모델의 안정성을 향상시킵니다. 예를 들어, 기울기 클리핑을 수행할 때는 gradient 값을 모니터링하고 임계값(threshold)을 설정하여 gradient가 해당 값보다 크면 스케일을 조정하여 gradient를 줄입니다. 이를 통해 gradient 폭발 문제를 완화할 수 있습니다.
- Gradient clipping
: gradient 크기가 일정 임계값을 초과하는 경우, gradient의 크기를 임계값으로 제한한다. gradient를 잘라내거나 스케일링하여 임계값 이하로 만든다. 이렇게 clipping된 gradient를 사용하여 weight를 update함으로써 weight의 큰 변화를 방지하고 모델의 안정성을 유지한다.
- Vanishing gradients ( Largest signular value < 1 ) //기울기 소실
vanishing되지 않게 하기 위해서 RNN architecture를 변경한다.
gradient가 소실되는 것은 RnN의 고질적인 문제이기 때문에 architecture를 변경해야한다.
RNN tradeoffs

RNN은 개념적으로는 말이 되는 것 같으나,, 문제가 많아서,,사실 잘 안 쓰인다.
그래서!! RNN의 gradient 폭발 및 소실 문제를 완화하여 나온 구조 중 하나가 LSTM이다.