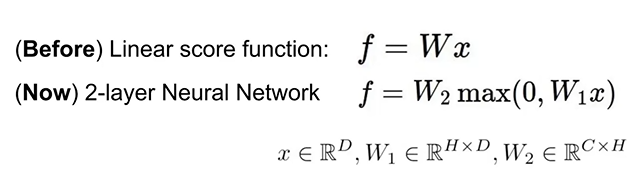ML - Neural Networks (NN) / Tensor / flattening / non-linear / activation function / ReLU
빈그레2023. 9. 14. 20:39
Neural Networks
Flow of Tensors
Neural Network의 module들은 결국 tensor들의 flow이다. input tensor와 중간중간의 featur map tensor들이 계속해서 흘러가는 것이며 그것들이 또 다른 module 의 input 으로 주어지는 흐름으로 neural network가 구성된다.
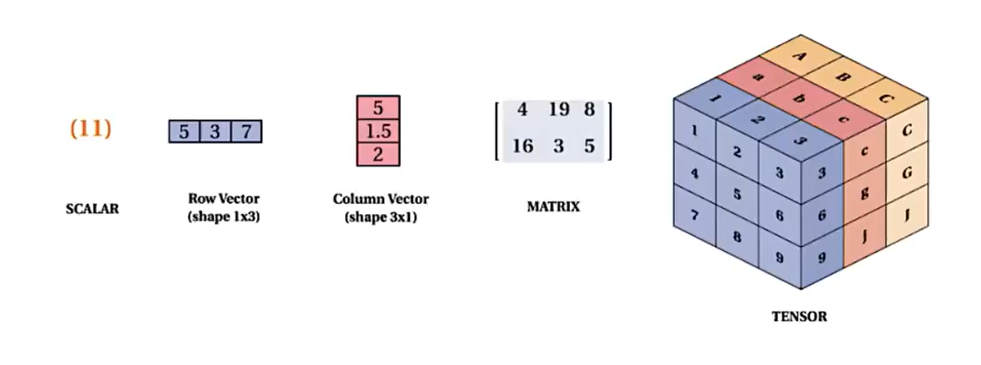
Tensor
: scalar부터 vector,matrix 등을 모두 총칭하는 general한 용어이다.
scalar는 0차원 tensor, vector는 1차원 tensor, matrix는 3차원 텐서라 할 수 있으나,
기준점을 어디에 두냐에 따라 차원은 달라질 수 있다.
tensor에서 차원은 보통 축의 개수를 의미한다.
Neural Networks (NN)
[ Artificial Neural Networks (ANNs) ]
: 인공신경망이라는 뜻으로, 사람의 실제 생물학적 신경망을 묘사한 알고리즘이다.
[ Neural Networks : without the brain stuff ] //뇌과학적인 것 없이 보는 관점
task 와 상관 없이 weight의 개수의 관점으로 봤을 때, linear하다는 것은 W를 곱해주는 개념인 것이다. linear는 가장 간단한 형태의 neural networks이다.
flattening (= vectorization) : 위 cat image는 32 * 32 * 3인 3차원 tensor로 표현할 수 있다. 하지만, 일반적인 Neural network에서는 이러한 공간 정보를 무너뜨리고 하나의 차원인 vector로 만들어준다. 이러한 과정을 vectorization이라 하기도 하고 flatten시킨다고도 한다.
10 class classification : linear classifier는 class의 개수만큼 차원을 가진다. 위 예시에서 f(x,W)가 10개의 차원을 가지므로 10개의 class 중에서 구분하려 한다는 것을 알 수 있다. image vector 3072*1 형태에서 f(x.W)를 10*1 형태로 만들어주기 위해 x 앞에 weights를 10*3072로 곱해주었다.
이러한 linear classification과정 이후 SVM과 softmax로 초기 분류 단계에서 얻은 결과를 보다 정확하게 조정하거나 원하는 형식으로 변환한다.
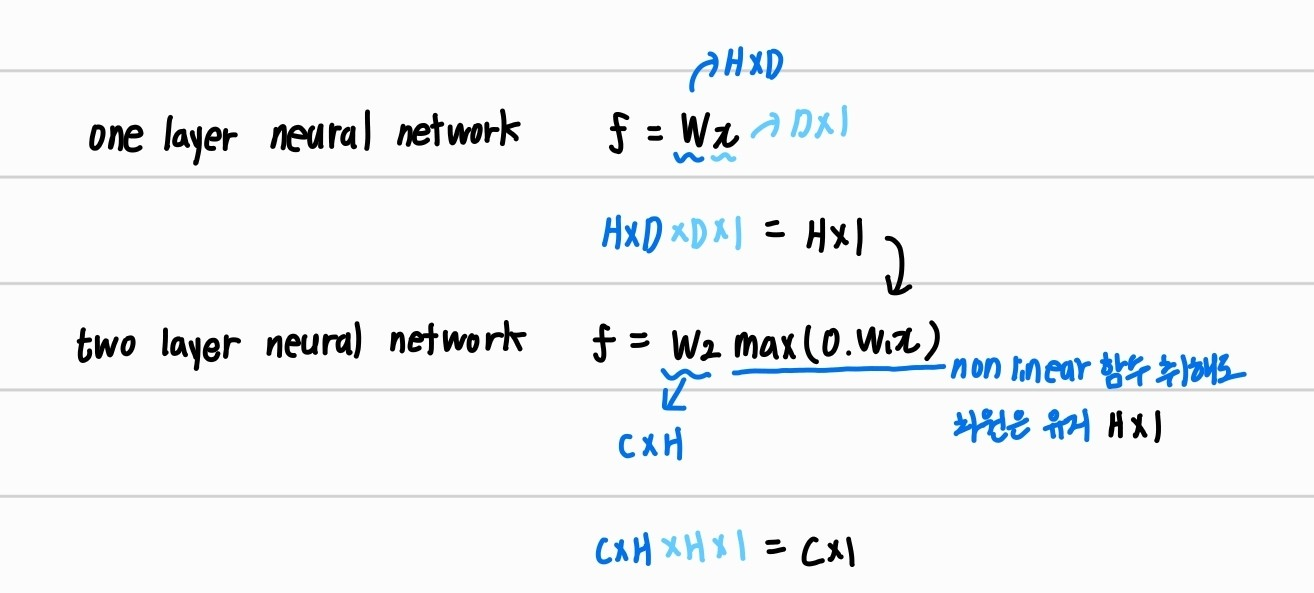
linear score function은 one-layer neural network이다. 바로 아래는 2-layer neural network를 표현한 것이며, one layer이후 two layer에서 이어 계산을 해준 것이다.
계산 과정은 다음과 같다. one layer값에 non-linear함수를 통과시켜주고 추가적으로 다시 W2와 곱해준다. non linear함수를 통과시켜도 차원은 유지되므로 matrix연산이 이어서 진행된다.
계산 과정에서 중간중간 intermediate layer에 대해서 hidden layer라고 한다.
가장 마지막 layer 에 대해서는 non-linear를 통과시키지 않는다. 마지막 layer이후에 svm이나 softmax 함수를 적용시킬 것인데 SVM과 softmax함수 자체가 non-linear하기 때문이다.
즉. 마지막 layer 에 대한 non-linear 처리는 SVM과 softmax와 같은 함수로서 대신한다.
(위 식들에는 bias가 생략되어있지만, 원래는 모든 layer 계산에 꼭 set로 포함시켜야 한다.)
non-linear함수의 필요성
- Activaiton function : 위에 쓰이는 max와 같은 non-linear함수를 activation function이라 한다.
Q. 아래와 같이 non-linear함수 없이 layer을 이어 곱하면 어떻게 될까?
non-linear 없이 계산하게 되면, weight를 나누어 곱할 필요가 없다....! 왜냐 하나로 합쳐버리면 되니까! layer를 쌓는 다는 건 직선로는 표현되지 않는 복잡한 mapping을 표현하기 위함인데, 중간에 non-linear를 넣지않으면 결국엔 그냥 linear한 함수가 되어버린다.
추가로는 이러한 이유가 있다.
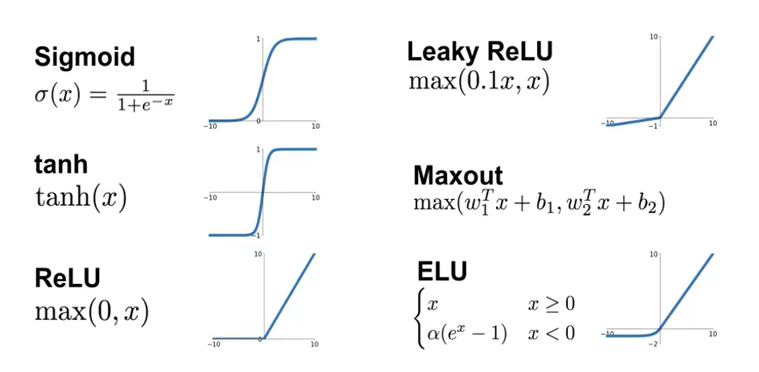
activation function
신경세포들 사이에 신호를 전달하기 위해서는 역치 이상으로 신호가 전달이 되어야한다. 이러한 역할을 하는 것이 activation function이다.
- activaiton function
원래는 sigmoid를 activaiton function을 많이 썼으나 최근에는 ReLU를 더욱 많이 사용한다. ReLU는 0보다 작을 때에는 0으로 mapping시키고, 0보다 크거나 같은 수에 대해서는 자기 자신의 값으로 mapping시킨다.
ReLU함수는 0이상에서 부분적으로는 linear하게 볼 수 있으나, 0에서 분명하게 꺾이므로 ReLU함수 전체로 봤을 때 non-linear하여 activation function으로서 적합하다.