Character-level language model
Word level Language model
: 주어진 텍스트나 문장을 이해하고 다음 단어나 토큰이 무엇일지 예측하는 잡업을 수행할 때 사용되는 것이 Language model이다. 예측은 문장의 맨 끝의 단어도 가능하고, 문장 중간에 있는 단어를 target word로 하여 예측하는 작업을 수행할 수도 있다.
구글이나 네이버에 어떠한 단어의 조합을 검색할 떄, 내가 자성하고 있는 단어 뒤에 올 단어를 이어서 검색창 아래쪽에 연관 검색어로 보여주는 것이 이에 해당한다.
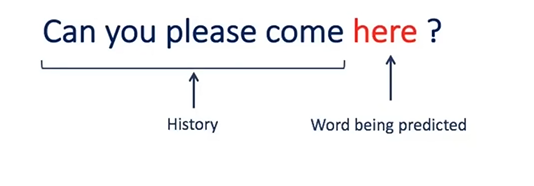
완벽한 문장에 구멍을 뚫어, RNN과 같은 model에 앞 단어들을 순차적으로 넣어주고, 마지막 출력을 예측하도록 한다.
이렇게 수많은 데이터를 학습하며 문맥 관계를 파악하고, 이렇게 학습시킨 weigth를 가지고, 빈 공간을 맞출 수 있는 weight로 학습시켜서 그 모델로 downstream task를 시키면 학습이 잘 된다.
downstream task : 모델이 훈련된 후, 실제로 사용자나 응용 프로그램에 적용되는 작업을 말한다.
위 예시는 word level language model이다.
Character-level language model
: 문제를 단순화시키기 위해 word level 대신 character level 을 다루어보자. (참고로 character는 알파벳 하나이다.
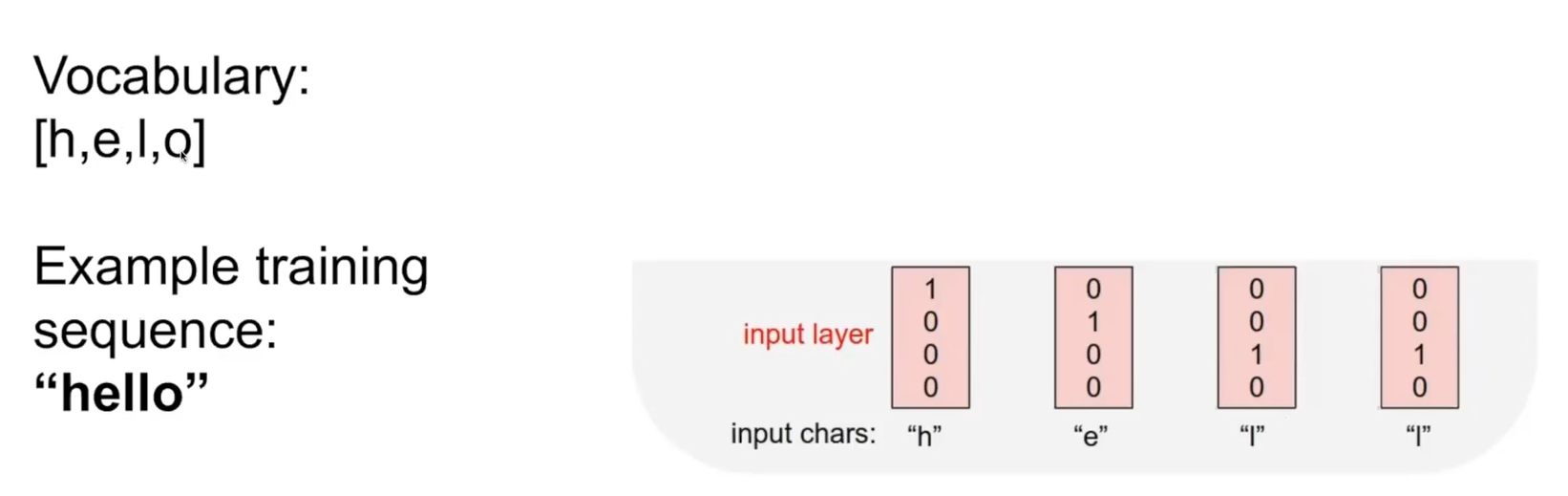
character level로 language model를 만들 때에는 다음과 같이 one-hot encoding이 쓰인다.
(*** one hot encoding : 단어 집합의 크기를 벡터 차원으로 하고, 표현하고 싶은 단어의 index에 1의 값을 부여하고 다른 index에는 0을 부여하는 단어의 벡터 표현 방식 )
위 예시에서 h라는 문자의 index가 0이므로 index[0]에 1이 들어가 1000이라 표현되었고, e는 index가 1이므로 1번째 위치에 1이 들어가 0100이라 표현되었다.
순서를 명확히 정리하면 다음과 같다.
1) 알파벳 문자 집합 정의
: 먼저 사용할 문자 집합을 정의한다. 위 예시에서는 hello에서 h,e,l,o가 쓰이므로 중복되는 것은 한 번만 작성하는 집합의 성질에 따라 [h,e,l,o]로 집합이 정의된다.
2) 문자에 대한 인덱스 부여
: [h,e,l,o] 각각에 대해 index가 부여된다. 여기서 h부터 0부터 순서대로 index가 부여된다.
3) one hot encoding vector 생성
: 각 문자를 표현하기 위해 해당 문자 index에는 1을 넣고 나머지에는 0을 넣은 이진 vector를 생성한다.
4) 텍스트 표현
: text를 문자 단위로 나누고 one-hot encodig vector로 표현하여 입력 데이터로 사용한다.
각 문자는 고유한 인덱스를 가지는 벡터로 표현되며, 모델은 이러한 벡터를 입력으로 사용하여 character 단위로 텍스트를 학습하고 생성할 수 있다. 하지믄 one-hot encoding은 대규모 어휘나 긴 텍스트를 다룰 때 메모리를 많이 소비하므로, 실제로는 embedding레이어와 같은 기술을 사용하여 효율적으로 문자를 표현하는 것이 일반적이다.
<one-hot encoding VS Embedding Layer>

[RNN of character-level language model]
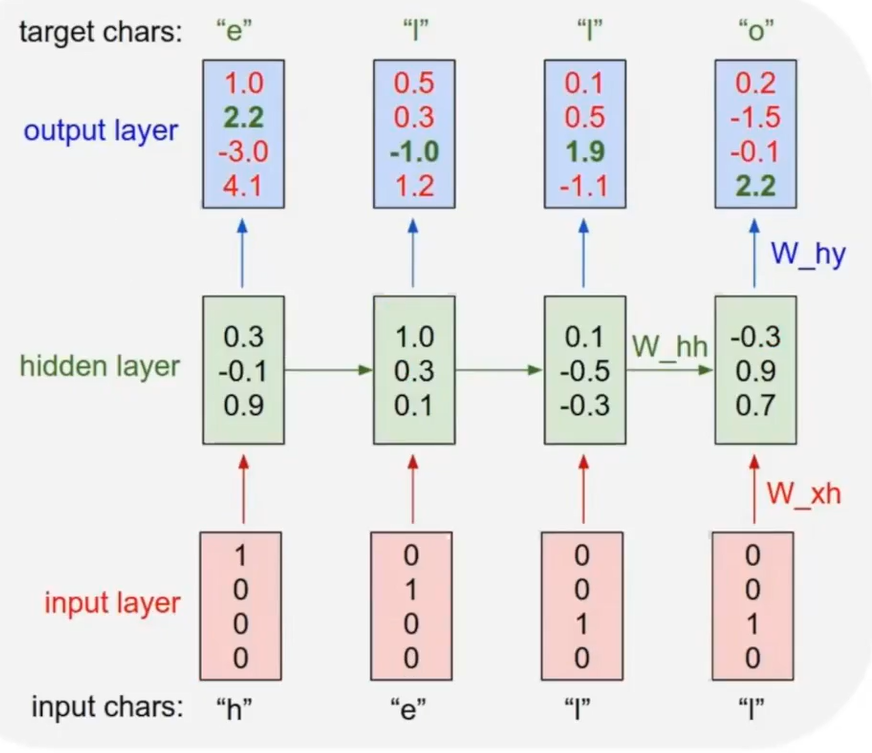
language model의 목적은 결국 다음번에 올 character나 word를 맞추는 것이기 때문에 target charcter는 다음에 와야할 문자가 된다. 따라서 위와 같이 input h에 대한 출력으로는 h 다음으로 와야할 e를 target으로 하여 weight matrix를 조정해나가며 weight를 update시킨다.
다음 단어가 항상 이전 time step에서의 Ground Truth로 쓰인다.
ground truth란 label과 비슷한 개념으로, 문제에 대한 실제 값(상태)을 나타내고, label은 보통 이미지 분류 작업에서 해다 이미지가 어떤 객체나 카테고리에 속하는지를 나태낼 때 쓰인다.

[Auto regressive model]
model을 test할 때엔는 feed back to model로 이전 time의 output을 input으로 넣어준다.
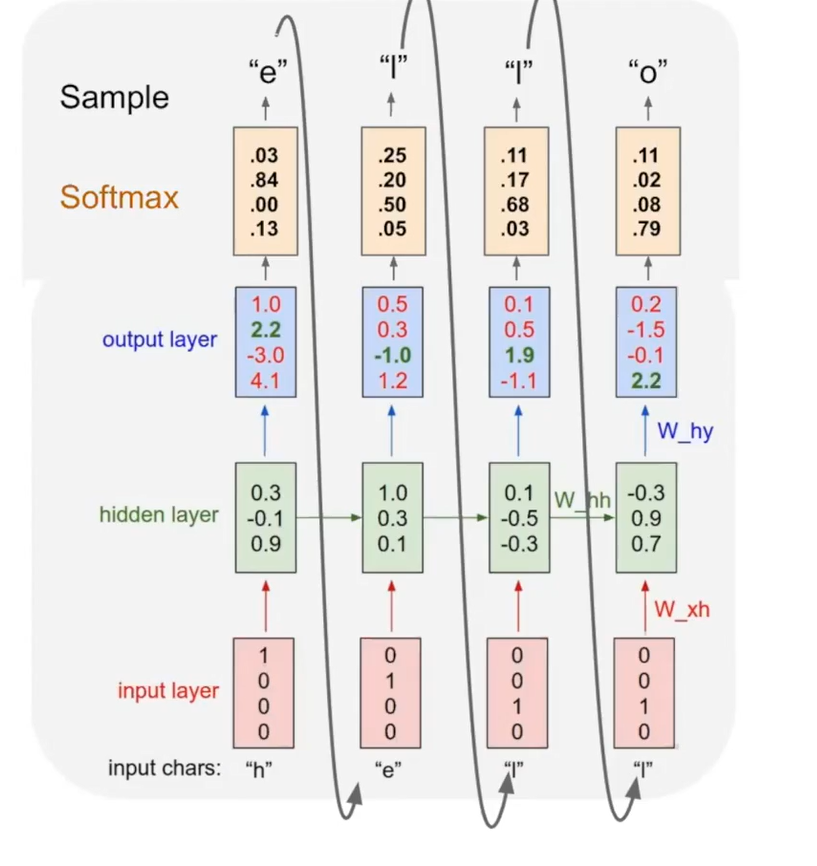
이렇게 자기 자신의 출력을 또 다시 input으로 활용하는 것을 Auto-regressive 라고 한다.