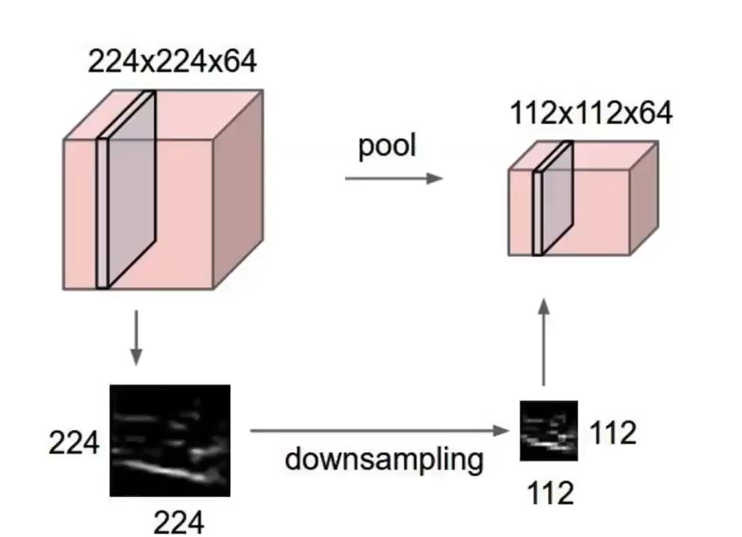
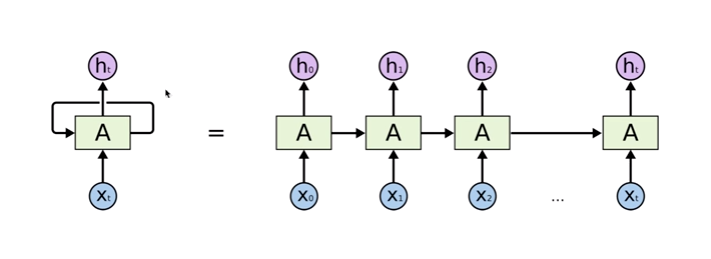
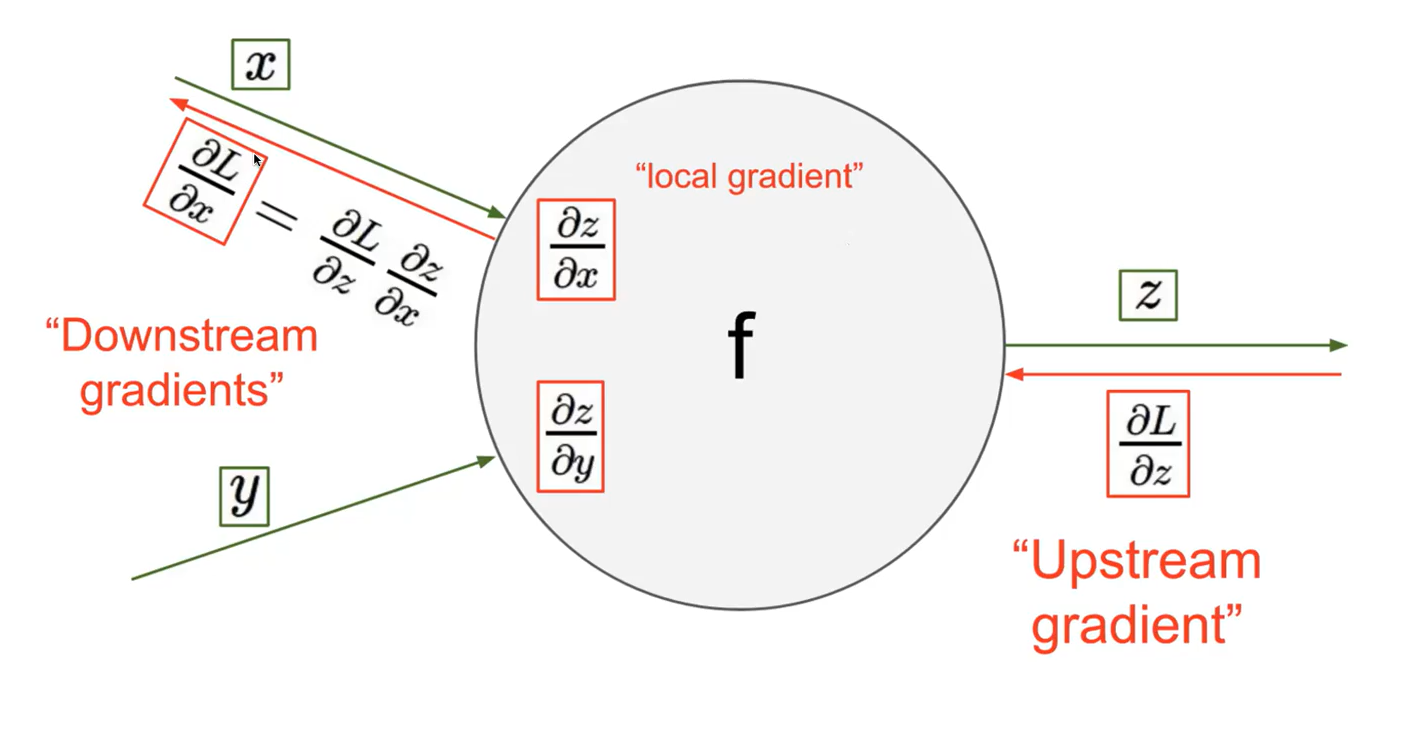
Pooling layer Pooling layer : Pooling layer는 입력 데이터의 공간적 차원을 줄이는 역할을 한다. 일반적으로 max pooling과 average pooling이 가장 많이 사용된다. pooling은 차원을 축소시키는 것이라 하였다. 위 예시를 보면 224*224 였던 차원이 풀링으로 인하여 112*112로 1/4배 줄어들었다. [pooling 특] - padding을 사용하지 않는다. - filter size와 stride size가 동일하다. Max Pooling pooling도 일종의 layer이기 때문에 filter의 개념이 있는데, pooling에서는 filter size와 stride size가 동일하다. 즉, overlapping 없이 연산이 진행된다. 겹쳐서..