ML - CNN / image 구성 / channel / filter / feature map / zero-padding
빈그레2023. 9. 21. 15:48
Introduction to CNN (Convolutional Neural Networks)
Neural Networks : without the brain stuff
CNN은 이미지 처리에 특화된 Neural Network이다. CNN을 다루기 전에 이전에 다뤘던 Neural Networks에 대해 복기해보는 시간을 가진다.
NN의 가장 간단한 형태로 linear score function을 다룬 적 있다.윗 수식은 one layer, 두번째 수식은 two layer까지를 표현한다. 여기서 W(weight)를 어떻게 설정하냐에 따라 차원을 변경시킬 수 있다.
weight를 거치며 3072차원 벡터가 100차원으로 바뀌고 weight2 matrx를 곱하고는 10차원이 되었음을 확인할 수 있다.
마지막 score에 대하여 softmax와 같은 non-linear function을 지나게 되기 때문에일반적으로 가장 마지막 weight를 곱한 이후에는 activation function을 곱하지 않는다.
classification 문제를 푸는 경우에는 가장 마지막 layer를 거치면 class개수만큼의 vector가 나온다. 따라서 위 예시는 class가 10개인 상황이라고 볼 수 있다. 각 10개의 class 별 score가 표현된 벡터일 것이다.
사실은 f계산식에 계속해서 bias가 더해져야 하나 위 수식에서는 표현만 생략된 것이다. 보통은 생략하나 있다는 사실은 인지하고 있어야한다.
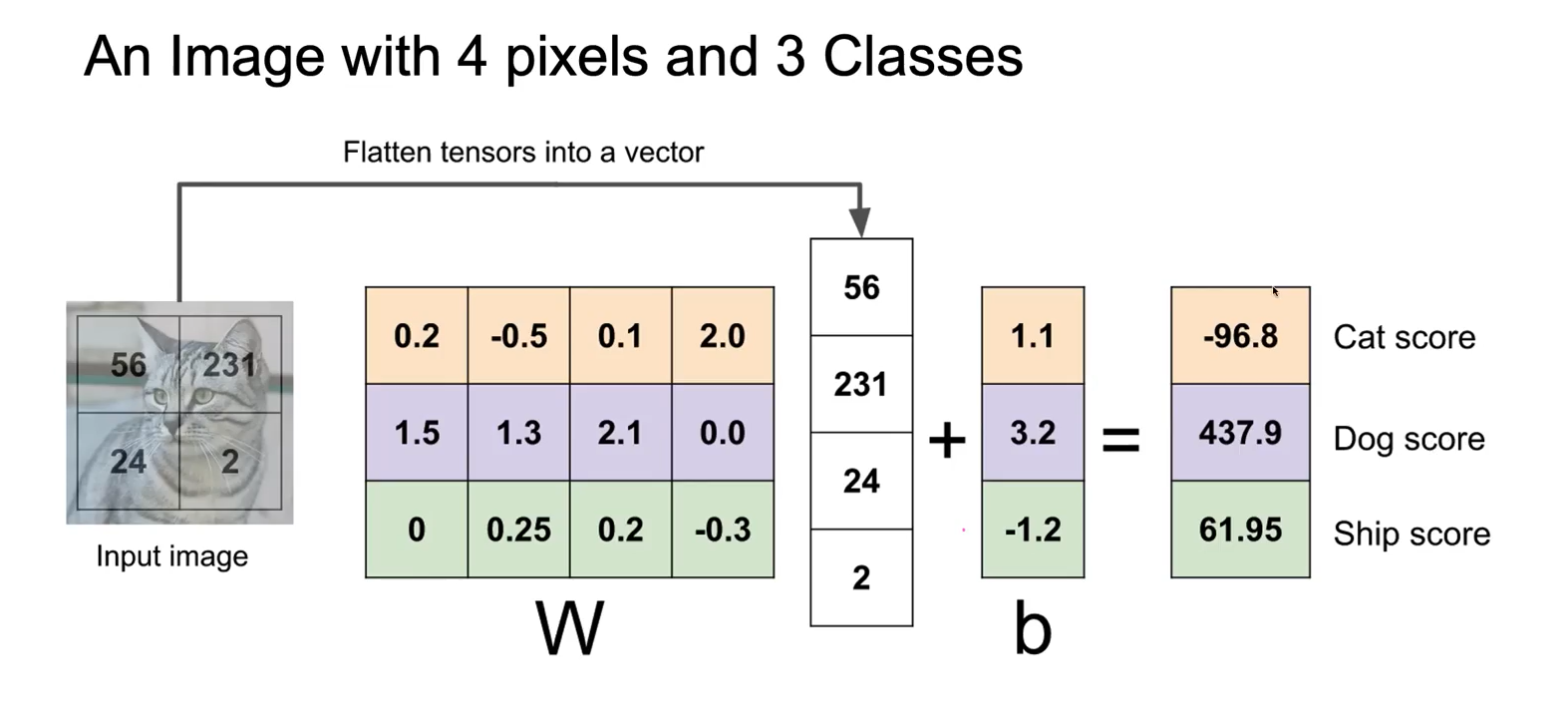
An Image with 4 pixels and 3 Classes
이미지는 width와 height를 갖고, 비슷한 곳에서는 비슷한 pixel값을 가질 확률이 높은데 이러한 공간적인 특징을 무시하고 vectorization시키면, 공간적인 정보의 특성이 유지가 되지 않는다는 단점이 있다.
1차원 결과는 공간 정보가 유실되었으니 결국, 이미지의 공간적인 구조 정보를 보존하면서 학습할 수 있는 방법이 필요해진다. 이를 사용하는 것이 합성 신경망(convolutional neural networks)이다.
*** 공간적인 구조 정보
: 거리가 가까운 픽셀들끼리 어떤 연관이 있는지,어떤 픽셀들의 값이 비슷한가지 등의 정보를 포함하고 있음.
CNN
CNN은 이미지 처리에 특화된 연산이다.
다음과 같이 이미지를 vectorization 시키지 않고 공간 정보를 보존하며 이미지를 통째로 넣어준다.
공간 정보를 보존한 채로 weight를 거친 결과들을 feature map이라 한다. 이를 크게는 feature vector라고도 하나 width나 height의 정보가 녹아있음을 표현하기 위해서는 feature map이라는 표현이 더욱 적절하다.
CNN의 핵심적인 특징은 공간정보를 유지하면서 feature map을 뽑아낸다는 것이다.
Basic Operation in CNN
Fully-connected layer
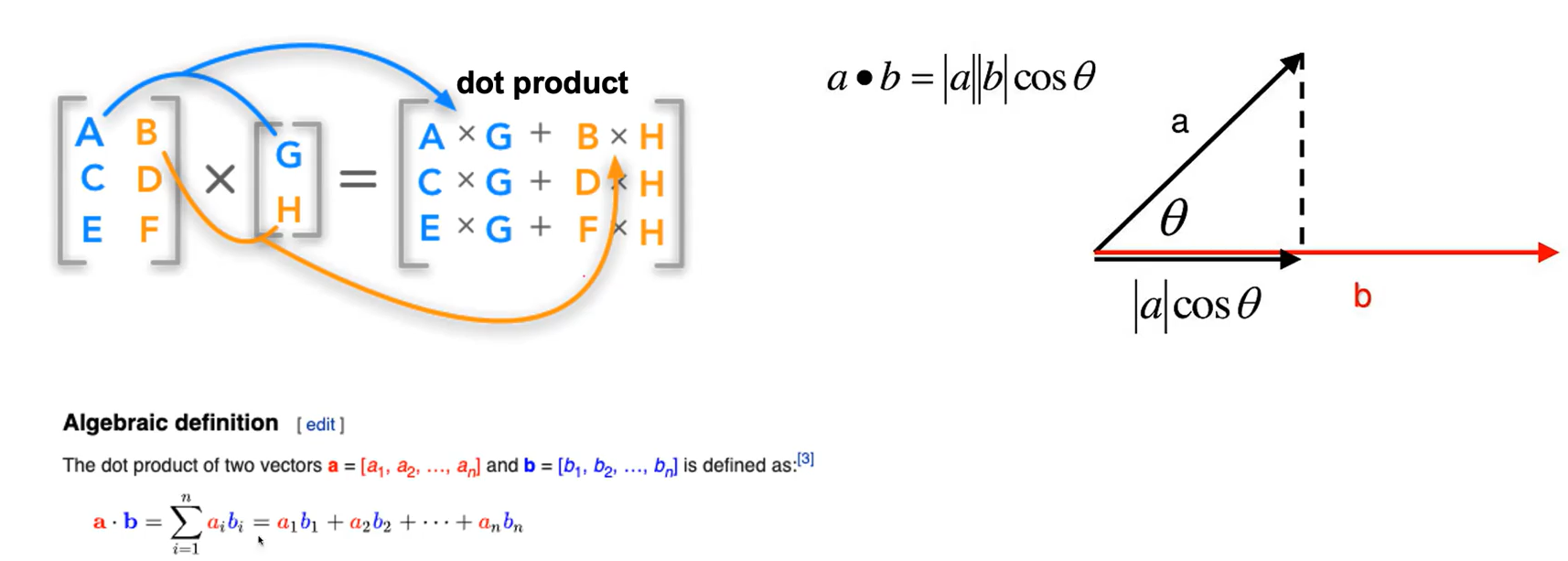
image를 vectorizaiton하여 연산하는 fully-connected layer에서는 3072번을 다 곱하며 내적의 과정을 거쳐야 한다.
(차원이 같은 공간상에 있는 두개의 벡터를 내적하면 같은 요소끼리 곱해 더한 값이 된다. )
하지만 이전 글에서도 언급했듯이 fully connected layer는 vectorization과정에서 공간적인 정보를 잃기 때문에 기계가 이미지를 판별하기 더욱 어려워진다. 이를 해결하기 위해 나온 것이 CNN이다.
Convolution
: 앞으로 다루게 될 CNN에서의 convolution도 fully-connected layer와 같이 내적과 연관이 깊다.
- 1) Image 구성
이미지는 높이,너비,채널로 구성된다.
- 2) Image 예시
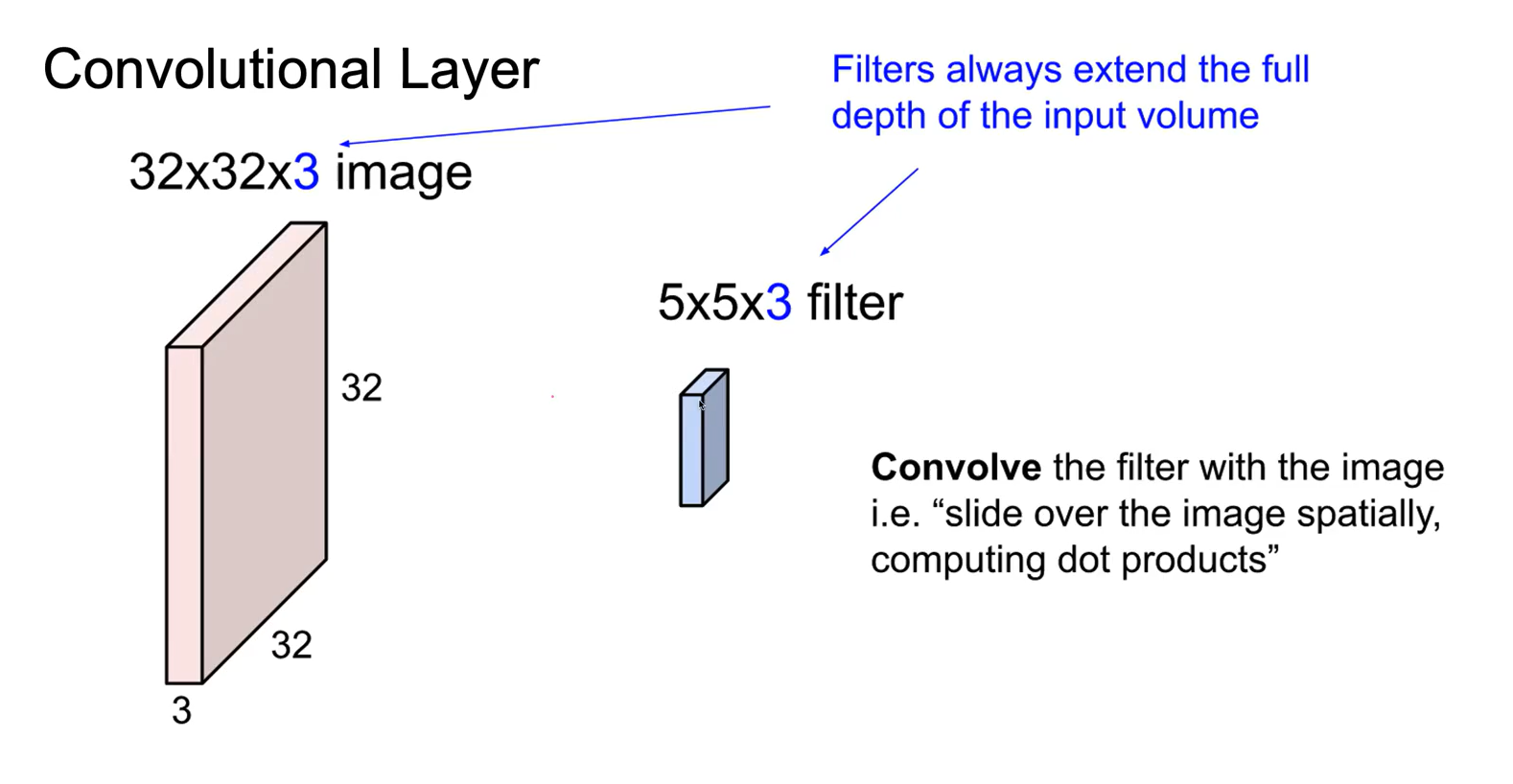
Convolutional layer 예시를 살펴보자.
위 이미지는 높이와 너비가 32이고 RGB 3 개의 channel을 가졌다.
- 3) filter / feature map
- filter filter의 요소값 하나하나는 weight(가중치)를 의미한다. filter의 차원은 정사각형의 형태로 32보다 작은 값으로 width와 heights를 가지나, channel 즉 depth는 input image와 똑같아야 한다. 이 filter로 input image의 좌상단부터 convolve한다. convolve한다는 것은 image라는 칠판을 filter라는 지우개로 훑듯이 지나가는 과정이라고 비유할 수 있겠다.
- feature map filter로 input image를 convolve한 output을 말한다. 공간 상으로 filter가 image안으로 들어가 convolution연산을 한다. convolution 연산은 필터와 이미지의 요소들의 값의 합으로 feature map의 요소 하나하나를 만들어낸다.
- 4) 여러개의 filter로 연산 후 new Image of size 28*28*6
위 예시는 6개의 filter로 convolution 연산을 하여 28*28*3의 featrue map이 생성된 것이다. feature map의 channel은 filter개수만큼 생긴다.
여기서의 가장 큰 특징은 공간 정보가 무너지지 않은 채로, learnable한 weight parameter인 filter로 학습을 시켜서 feature map이 완성되었다는 것이다.
- 5) feature map의 크기 감소
filter로 convolution 연산을 하면 feature map으로서 나온 new image의 값이 계속해서 줄어드는데, 이미지의 크기가 너무 빠르게 줄어들면 원하는 결과를 얻기 어려워진다.
A closer look at spatial dimensions
stride
: 스트라이드는 convolution 연산에서 filter가 데이터 위를 이동하는 간격을 나타내는 파라미터이다.
스트라이드의 개념을 예시로 설명하기 위해, 실제로는 image의 channel은 RGB를 하나씩 구성하기 위해 3d로 표현되나, one-demsnsion으로 임시로 표현하였다.
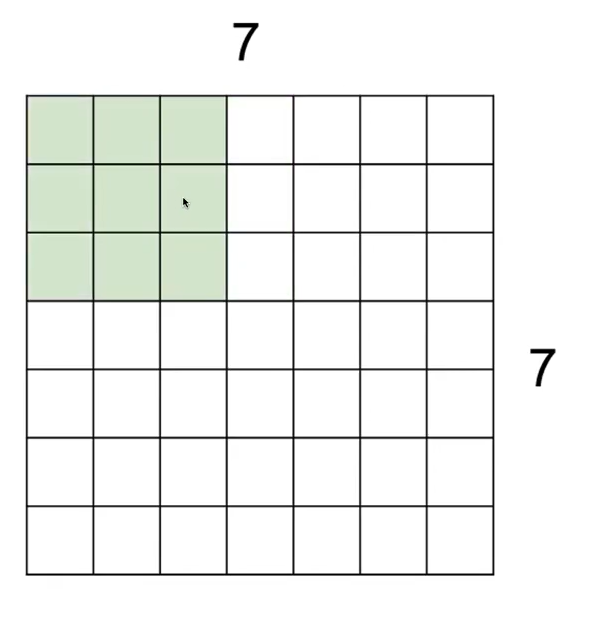
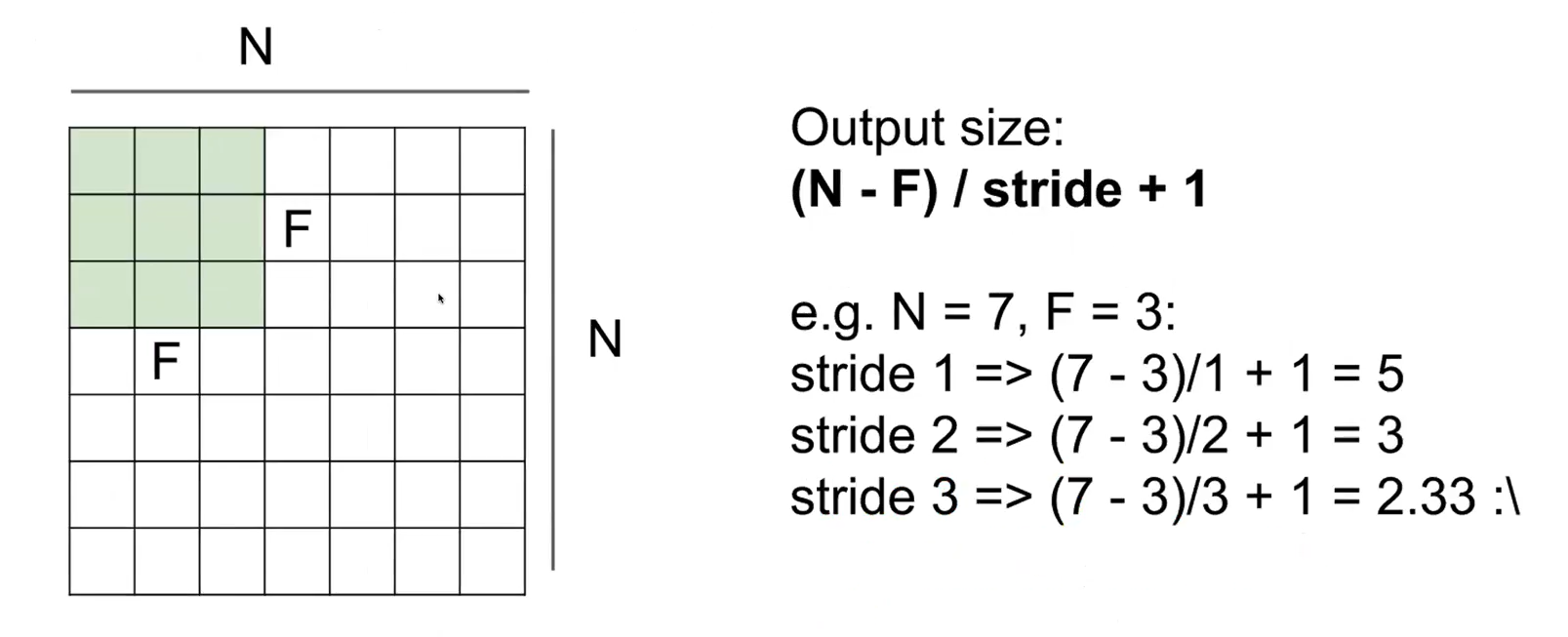
포개진 영역으로부터 하나의 값을 구하고, 오른쪽으로 이동시키며 값을 계속해서 구한다. 이런 원리로 stride가 1인 상태로 slidng하면 5*5의 output이 나올 것이다.
위 예시는 stride가 1 이라서 한칸씩 이동한 것이나, stride는 사용자 지정이 가능하다
만약 stride가 2라면 7칸에 대해서 3번의 연산만 진행하면 되기 때문에 3*3 feature map이 output으로 나올 것이다.
그런데 stride가 3인 경우에는 두번 연산하고 한칸이 남는다. 이러한 경우에는 handling하기가 어렵기 때문에 유효한 stride값으로 보지 않는다.
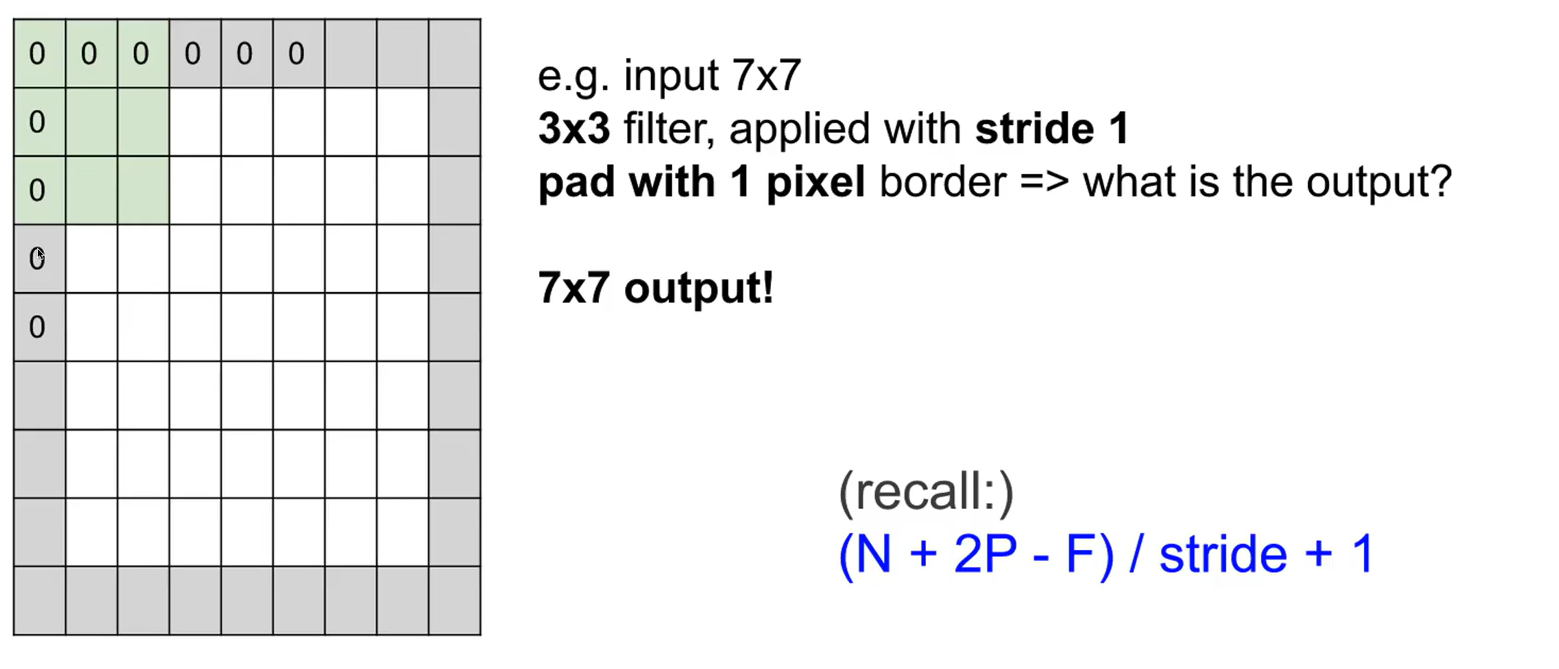
만약 stride를 3으로 해야한다면, 입력 이미지 주변에 0으로 채워진 픽셀을 추가하는 zero padding을 이용하는 것이 하나의 방법이 될 수 있다. 이렇게 하면 연산 후에도 출력 특징 맵의 크기가 입력과 동일하게 유지된다.
output(feature map) size
Zero padding
: stride값에 의해서 output size가 정수로 떨어지지 않는 상황에 zero padding을 사용할 수 있다.
zero padding이란, 0이라는 아무의미도 없는 값을 테두리에 추가해주는 것을 말한다.
패딩을 몇 겹으로 넣을지를 P라는 parameter로 표현한다. 위 좌측 예시의 경우는 P가 1인 경우이다.
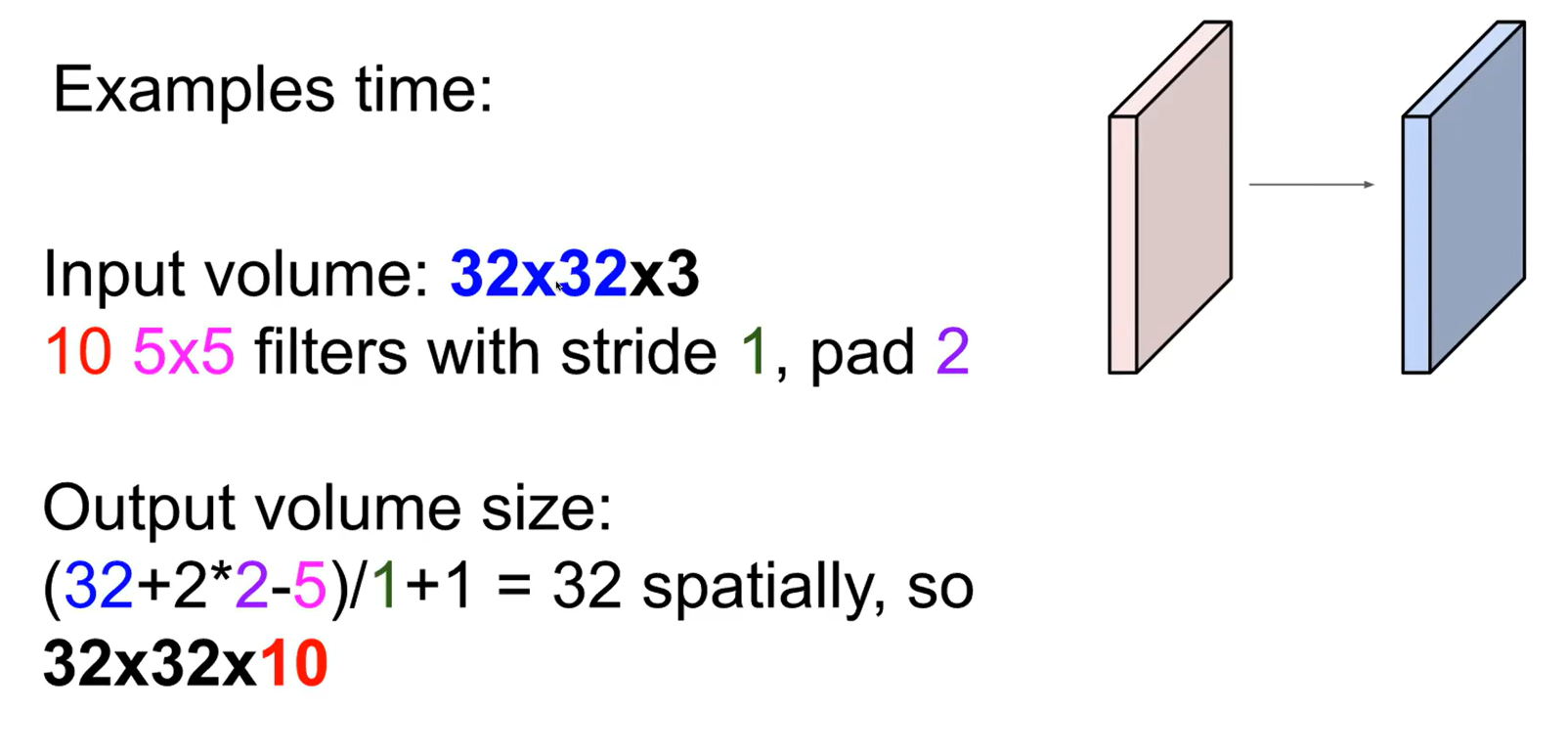
zero padding애서 filter size보다 1작은 수를 절반한 값을 zero padding size로 넣으면, input image와 크기가 같은 feature map을 얻을 수 있다.
one by one convolution
: 기존에 쓰였던 3x3 filter는 공간상에서 3*3=9개 점에 대한 연결성을 learnble한 parameter를 거쳐서 관계를 응축시켜 9개가 1개의 점으로 mapping된 것이었는데, 픽셀관의 관계를 고려하지 않고 그냥 차원을 늘리거나 줄이기기 위한 용도로 1x1 convolution은 쓰기도 한다. 이는 비선형성을 추가하기 위해서도 쓰인다.
Examples time:
convolution의 filter 개수가 random할 수는 있지만, input과 output에서의 차원은 일정하게 만든다.