AI - Lab 04 Supervised Learning and Optimization / Linear Regression / K-NN regression
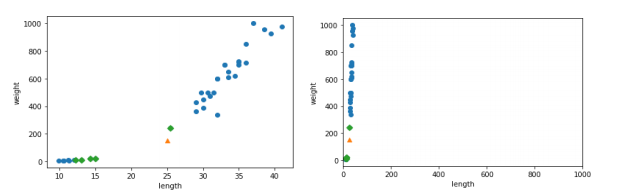
graph의 scale을 1000으로 맞추면 우측처럼 구분이 어렵고, 왼쪽처럼 하면 nearist가 너무 멀어서, 이렇게 정규화를 해서 비교 단위가 영향을 주는 factor가 될 수 있으니, 데이터를 정규화시키는 것이 중요하다 K-NN은 학습은 데이터를 저장하면 끝나는 것이고, 내가 가지고 있는 모든 데이터들과의 거리를 비교해서 가장 가까운 이웃들을 보는 것이다. 가장 가까운 K개를 뽑아서 투표를 하는 것! K=1일 때 중앙 노란 부분에 찍히면 주변이 다 초록인데도 노랑으로 분류되니까, K를 좀 늘려서 튀는 값들을 무시할 수 있도록 조정해준다. K가 너무 작으면 예외적이 것들에 영향을 너무 많이 받고, 너무 크면 분류가 잘 안된다. (그냥 데이터 많은 걸로 분류됨) 내가 가진 모델이 표현력이 충분하지 않..