VDMC - Test Model "TMMv1"(1) / Preprocessing / inter-prediction / inter vs intra / mesh buffer / 1:1 mapping
빈그레2024. 1. 25. 21:45
intra vs inter
intra
: 모든 frame에 대해서 완전하게 모두 압축하는 방식
inter
: I-프레임에 대해서만 (보통 3frame 주기로) 완전히 압축하고 나머지 P-프레임에 대해서는 일부 정보에 대해서만 압축하여 압축의 효율을 높이는 방식
I-frame에 대한 정보를 mesh buffer에 저장해두었다가 추가적으로 얻은 enhancement vector 정보 및 다른 정보들을 통해 p프레임들을 만든다.
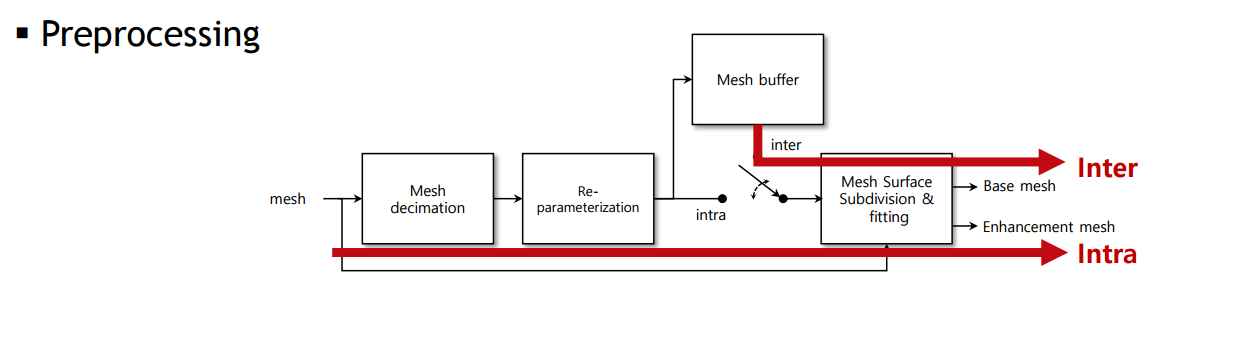
Preprocessing
입력으로 3D mesh를 받으면 inter mode인지 intra mode인지에 따라 서로 다른 path를 가지게 된다. inter-prediction이 필요한 intermode와 그렇지 않고 독립적으로 수행하는 intra mode로 나뉜다.
// inter prediction 개념 아래에 따로 설명
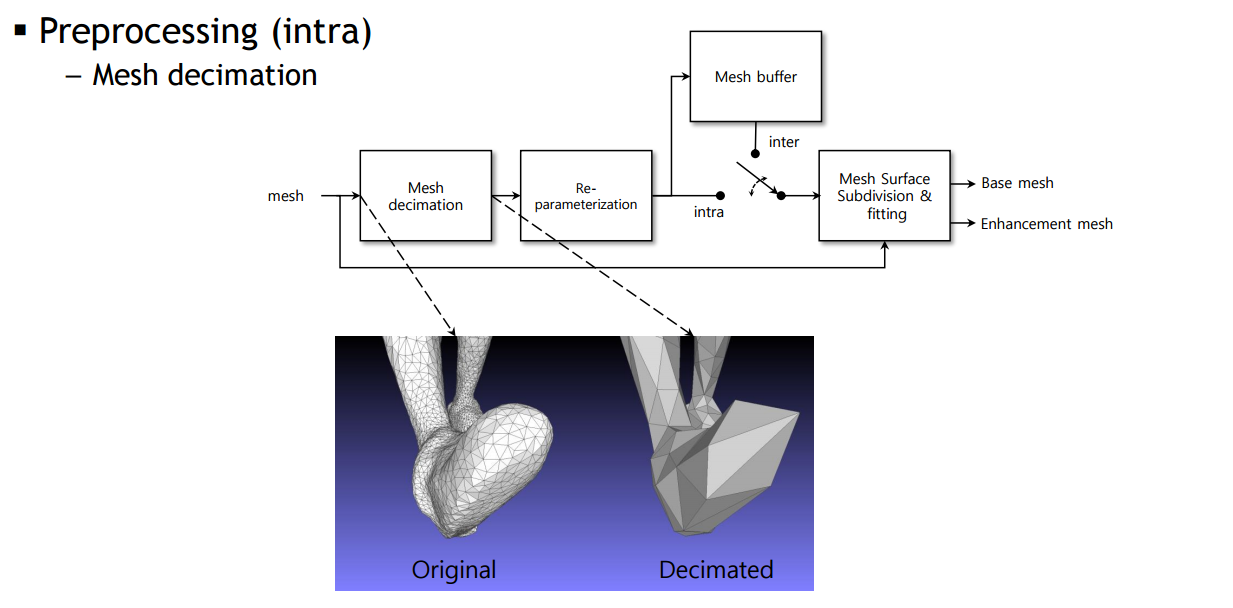
** Mesh Decimation : 3D 모델의 복잡성을 줄이기 위해 메시의 정점(vertex), 엣지(edge), 그리고 면(face)의 수를 감소시키는 과정이다. 모델의 시각적 품질을 가능한 유지하면서, 메모리 사용량을 줄이고, 렌더링 시간을 단축하며, 파일 크기를 감소시키는 데 목적이 있다.
** Mesh Decimation의 주요 기술
Vertex Decimation: 정점을 제거하고 인접한 면들을 재구성함으로써 메시를 단순화합니다. 중요도가 낮은 정점(예: 시각적 영향이 적은 위치에 있는 정점)부터 제거합니다.
Edge Collapse: 두 정점을 연결하는 엣지를 하나의 정점으로 축소하여 해당 엣지는 사라진다. 이 방법은 메시의 형태를 유지하면서 정점의 수를 줄입니다.
Face Decimation: 면의 수를 줄임으로써 메시를 단순화합니다. 이는 일반적으로 크기가 작거나, 시각적으로 덜 중요한 면을 제거함으로써 이루어집니다.
Clustering: 공간을 그리드로 나누고, 각 그리드 셀 안에 있는 정점들을 대표하는 단일 정점으로 군집화합니다.
Quadric Error Metrics (QEM): 오류 메트릭을 사용하여 각 decimation 단계에서 발생하는 형상의 변화를 측정하고, 이를 최소화하는 방향으로 메시를 단순화합니다.
PreProcessing 단계에서 좌측 orginal mesh를 simplify해서 적은 수의 face(면)을 갖도록 decimation을 한다.
위와 같은 Edge contraction기술을 사용하여 decimation이 진행된다. 간단히 설명하면 before에 있는 중앙 두개의 vertex를 after처럼 하나의 vertex로 만들어주는 것이다. 위와 같은 과정으로 여러번의 iteration을 돌면서 orginal data를 decimated data로 만들어준다.
이렇게 만들어진 decimated data를 바탕으로 re-parameterization 과정이 진행된다. decimated mesh가 되면서 original mesh로부터 약간의 변형이 생기기 때문에 이러한 부분에 대해서 decimated된 mesh를 original mesh에 맞추어 re-parameterization 한다. 이러한 과정을 거치면 orginal data가 좀 더 sparse한 mesh의 형태로 바뀌어, uv coordinate과 coverture들의 연결성이 coding하기 좋은 형태로 변경이 된다.
re-parameteried된 mesh는 mesh buffer로 들어가서 inter mode를 위해 저장이 된다.
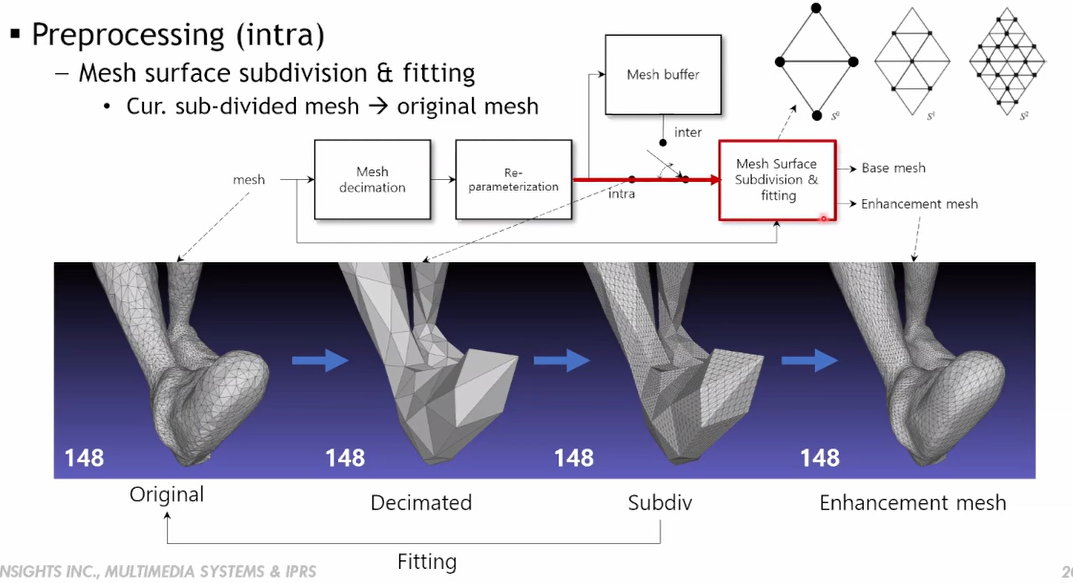
이 과정이 apple이 제안한 기술의 핵심이라고 할 수 있다. 148은 POC number인데 intra이기 때문에 모두 같은 number를 가진다. *** POC (Picture Order Count) : 인코딩된 프레임의 순서를 나타내는 데 사용된다.
mesh surface를 sub-division한다고 볼 수 있다. 삼각형을 4개의 작은 삼각형으로 분할하고 이를 재귀적으로 반복해서 점점 더 많은 vertex를 생성해내는 방법이다.
데이터 크기를 감소시키기 위해 decimation된 mesh에 대해서 sub-division을 통해 잘게 만들고, 이를 orginal에 fitting을 하여 subcivision된 vertex들이 orginal의 vertex들과 가까워지도록 한다. 이는 encoder 상에 구현되어있다.
sub-division된 mesh와 original mesh와의 차이를 enhancement vector 혹은 displacement 라고 한다.
fitting을 하면 enhacement mesh와 같이 smooth하게 coverture가 표현된다. ..//나중에 다시 확인
Preprocessing 과정에서의 (1)decimated mesh가 base mesh이고, sub-division된 mesh와 original mesh와의 차이를 (2)enhancement vector 혹은 displacement 라고 한다.
preprocessing's output = (1) , (2)
inter mode의 경우에 대해서 이렇게 진행된다. 이전에 다루기 쉬운 data 형태로 decimate하여 mesh buffer에 저장해두었던 것을 꺼내와서 intra mode와 동일하게 surface를 sub-division을 하고 fitting을 하게 된다.
reference mesh는 146번째 frame의 mesh를 가져와서 sub-division을 동일하게 하고, 현재 frame인 148번 frame과 동일하게 fitting을 하게 되면 enhancement mesh가 orginal mesh와 거의 동일하게 나오게 된다.
decimation된 mesh의 각각의 vertex들과, enhancement mesh를 다시 sub-division한 base mesh와의 position 차이값만 전송이 되는 방법이 사용된다.
inter prediction을 위해 현재 vertex와 이전 frame의 vertex를 1:1로 mapping하는 것이 어려운데, apple은 mesh buffer에 저장해두었던 이전 frame의 mesh를 현재 프레임에 fitting을 하면서 강제적으로 1:1 mapping을 하게 되었다.
inter prediction할 vertex가 이미 1:1 mapping이 되어서 위치 간의 차이값(motion vector)만 전송을 해주면 되는 상황이다. //connectivity도 동일하게 사용하면 됨...(?)
inter prediction을 위한 걸 preprocessing에서 이미 처리를 해버림!! 핵심 기술..!!
사이드 개념 " Inter Prediction "
: 현재 프레임을 인코딩할 때, 이전이나 이후의 프레임에서 비슷한 콘텐츠를 찾아 그 정보를 참조함으로써 데이터를 압축한다. 예를 들어, 영상에서 움직이는 물체가 있을 때, 물체의 배경은 거의 변하지 않지만 물체 자체는 위치가 바뀐다. Inter prediction은 이러한 변화(움직임)만을 기록함으로써 전체 프레임을 다시 인코딩하는 대신에 변화된 부분만을 저장한다.
Motion Estimation (움직임 추정): 현재 프레임과 이전 프레임을 비교하여, 각 블록 또는 매크로블록의 움직임을 추정합니다. 이 과정에서 가장 유사한 블록을 이전 프레임에서 찾아내고, 그 위치의 변화를 모션 벡터로 표현합니다.
Motion Compensation (움직임 보상): 모션 벡터를 사용하여 이전 프레임의 블록을 현재 프레임에 맞추어 움직입니다. 이를 통해 현재 프레임에서 해당 블록이 어떻게 변화되었는지를 예측합니다.
Residual Coding (잔차 코딩): 실제 프레임과 움직임 보상으로 얻은 예측 프레임 사이의 차이(잔차)를 인코딩합니다. 이 잔차는 일반적으로 원본 데이터보다 훨씬 작은 정보량을 가지고 있어, 효율적인 압축이 가능합니다.
이점 : 프레임 간 중복을 제거함으로써 데이터를 더 작게 압축할 수 있어 더 효율적인 전송이 가능해진다.
단점 : 계산이 복잡해지고 움직임 추정 및 보상 과정으로 인코딩과 디코딩에 latency가 증가할 수 있다.