VDMC - "What's the Video-based dynamic mesh coding?"
빈그레2024. 1. 24. 21:34
Video-based Dynamic Mesh Coding
Contents
- What's the Video-based dynamic mesh coding? - V-DMC CfP results - V-DMC Test Model version 1 (TMMv1) - Other technical adoptions
What's Mesh
: 3D 모델의 구조를 나타내는데 사용되며, 모델을 구성하는 꼭짓점, 선, 삼각형 또는 다른 다각형 집합체를 나타낸다.
이러한 메시 구조는 3D모델을 시각적으로 렌더링하거나 다양한 3D 그래픽 작업을 수행하는데 사용된다.
메시는 3D 모델을 디지털로 표현하는 방법 중 하나이다. 일반적으로 꼭짓점(Vertex), 에지(Edge), 면(Face) 등으로 이루어져 있다. 각 꼭짓점은 3D 공간에서의 좌표를 가지며, 선은 꼭짓점을 연결하고 면은 선들의 조합으로 구성된다.
What's the Video-based dynamic mesh coding?
- Example of Dynamic mesh
mesh는 dense하여 point cloud보다 data양이 더 많을 수 있지만, 그런 dense한 mesh들은 cdc에서 빠진다../.? cdc가 뭐임
-> 따라서 dynamic mesh 에서는 상대적으로 sparse한 data를 다룬다.
dynamic mesh는 30fps(frame per second) 정도로 빠르게 움직이는 motion이 많은 data이다.
// 실시간 처리를 위해서는 일반적으로 30fps 이상이 필요하며, 이는 한 프레임당 33.33ms 이하의 처리 시간이 필요하다는 것을 의미한다. 즉 1초(1000ms)에 30frame이상이 부드럽게 지나갈 수 있도록 frame당 처리시간이 33.33ms 내로 해결되어야한다.
"Video based dynamic Mesh Coding"은 비디오 데이터를 효율적으로 표현하고 압축하는 방법 중 하나이다. 비디오 내의 객체나 장면을 mesh라는 형태로 모델링하여, 각 프레임에서의 움직임과 변화를 효율적으로 코딩할 수 있도록 해준다.
위에서도 언급하였듯이 mesh는 vertex와 이를 연결하는 edge로 구성된다. dynamic이라는 용어는 mesh가 시간에 따라 변화할 수 있음을 의미하며, 이는 비디오의 각 프레임에서 객체의 움직임이나 변형을 표현할 수 있도록 해준다.
//frame 자체는 정적인 이미지 한장일텐데,, 프레임에서 움직임을 표현한다는 게 어떤 의미지?? 그냥 이전 프레임과 변화도를 표현하고 있다는 말인가
Video based dynamic mesh coding의 목표는 비디오 데이터를 표현하고 전송하는데 필요한 비트량을 줄이는 것이다. 이를 통해 저장 공간을 절약하고, 네트워크를 통한 전송 시간을 단축할 수 있다.
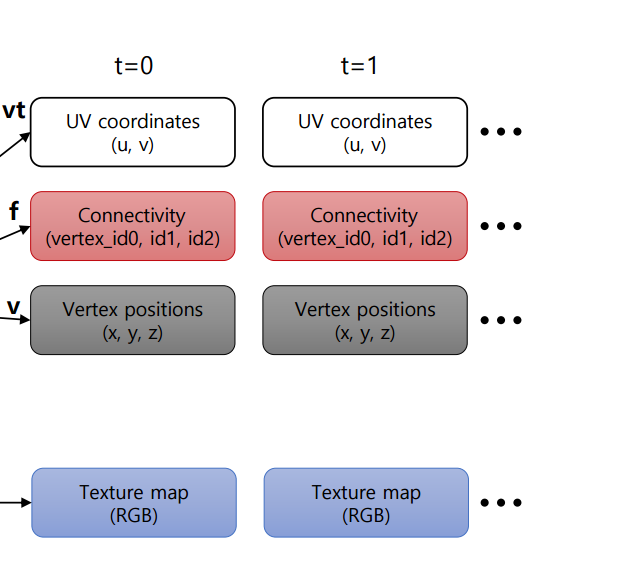
Dynamic mesh data structure
VDMC에서 사용하는 data의 dynamic mesh structure는 이렇게 구성되어 있음
-Geometry : 3D 공간상에서의 점 좌표(vertex)들에 대한 position 정보
Vertex : 3D 공간에서의 한 점을 의미하며, 3차원 공간에서의 위치를 x,y,z로 정의한다. 3D 모델링에서는 여러 vertex들을 연결하여 선분, 면, 그리고 최종적으로는 3D 모델의 형태를 만든다. vertex는 모델의 모양, 크기, 위치 등을 정의하는 중요한 데이터를 포함한다. //위치 정보 중심
Connectivity : vertex들의 index로 vertex들의 연결을 표현// id0,id1,id2 mesh의 기본구조는 삼각형인데 이를 이루려며 3개의 vertex가 필요하다.
UV coordinates(u,v) : 각각의 vertex가 어떤 속상 값들을 가질 수 있는지 u,v 좌표를 가지고 있음 uv 좌표계는 주로 3D 모델 표면에 2D 이미지를 mapping하기 위한 시스템이다. 3D 좌표계에서 x,y,z축을 사용하는 것과 달리, uv 좌표계는 2d 이미지의 가로,세로 축을 의미하는 u,v 좌표 체계를 사용한다. 3D 모델의 각 vertex에 해당하는 uv 좌표를 가진다. 이 좌표들은 모델에 텍스처를 올바르게 매핑하는 데 사용된다.
Texture mapping : 3D 모델에 2D 이미지를 적용하는 과정이다.
: texture map을 Attribute 그 자체로 보면 된다. Geometry에서 공간 정보를 2d로서 u,v coordinate로 알려주면 uv coordnates는 rgb 정보를 갖고있는 texture map에서 해당 uv위치에 해당하는 색상이 어디인지를 mapping하는 좌표이다.//으아 여기 말 이상해 나중에 다시 정리해
암튼!! 3D공간상의 위치를 uv coordinates로 표현하고, texture map에서 해당 좌표에는 그 위치에서 가져야할 색상 정보를 가지고 있다.
3D 객체에 2D 이미지(텍스처)를 적용하여 사용자에게 보다 사실적이고 상세한 2D 이미지로 렌더링된 결과를 보여주는 과정이다. 이 과정에서 3D 모델의 표면에 위치 정보와 색상 정보 등이 포함된 2D 텍스처가 매핑되어, 빛의 반사, 질감, 그림자 등 다양한 시각적 효과를 모사하며 최종적으로 렌더링된다. 결과적으로, 이는 3D 모델을 더욱 실감나고 세밀하게 표현하는 데 기여한다.
[1] uv unwrapping : 3D 모델의 각 면을 2D 평면으로 펼치는 과정이다. 이를 통해 각 꼭짓점에 uv 좌표가 할당되며, 이 좌표는 모델의 표면에 texture를 어떻게 배치할지 결정한다. 모델을 펼칠 때 어디에서 절단할지 결정한다. 보통 3d 모델의 가장자리(edge)로 설정되며 이 절단선은 3d모델을 2d 평면으로 펼칠 때의 기준이된다. 절단선을 기준으로 펼치면(unwrapping) 모델의 각 면 (face)이 2d uv 평면에 매핑된다. uv 맵이 생성된 후에는 texture의 왜곡을 최소화하도록 조정이 이루어진다. [2] texture mapping : 펼쳐진 3D 모델의 각 면에, 2D 텍스처 이미지가 매핑된다. [3] Rendering : 최종적으로 모델이 렌더링되며, texture가 적용된 모델이 사용자에게 보여진다.
각각의 vertex들이 이러한 uv coordinates의 어느 좌표에 있는지 mapping된다.
time 축으로 봤을 때, 이렇게 세로로 한세트로 보면 된다.
-Attribute : 3차원 object의 최외각 coverture을 표현하는 속성 정보 //R,G,B data
3차원 object의 가장 겉면을 표현하는 색상 정보들의 texture(2d) map이 존재
Encoding
Geometry부를 먼저 encoding하고 그 결과를 이용해서 attribute를 encoding한다. 이후 두 coding 결과값을 같이 muxing해서 bitstream으로 출력하게 된다.
3차원 volume data를 비디오 기반으로 압축하는 V3C 표준으로 compression하였다. V3C는 "Versatile Video Coding for Point Clouds"의 약어로, MPEG에서 개발한 포인트 클라우드 데이터를 위한 압축 표준이다.
V3C 압축 표준은 크게 두 가지의 주요 구성 요소로 나눌 수 있다.
1.지오메트리(Geometry) 데이터 압축 : 이는 3차원 공간에서 포인트 클라우드를 형성하는 점들의 위치 정보를 압축하는 과정이다.지오메트리 정보는 각 포인트의 X, Y, Z 좌표로 구성되며, 이러한 정보는 시각적 표현과 관련된 정밀도를 유지하면서 압축되어야 한다. 2.속성(Attribute) 데이터 압축 : 이는 포인트 클라우드의 각 점에 부여된 추가적인 정보, 예를 들어 색상(RGB)이나 반사율(intensity) 같은 속성 데이터를 압축하는 과정이다. 속성 데이터는 3D 장면의 시각적 디테일을 향상시키는 데 중요하다.
VPCC (Video-based Point Cloud Compression)
위 coding 방법과 유사한 encodig순서를 가지는 VPCC에 대해 간단히 언급해보겠다. VPCC란 point cloud data를 효율적으로 압축하기 위한 비디오 기반 기술을 말한다. video-based point cloud compression도 위 mesh compression과 동일하게 geometry 정보 먼저 압축하고, 그것을 바탕으로 attributes 정보를 압축한다.
- point cloud : 3D 공간의 점들의 집합으로 구성된 데이터 구조이며, 각 점은 공간상에서의 위치(x,y,z)와 추가적인 색상,강도 등의 정보를 포함한다. 이러한 point cloud data는 자율주행 자동차,로보틱스,AR,VR,3D mapping 등의 분야에 사용된다.
VPCC 기술은 이러한 포인트 클라우드 데이터를 효과적으로 압축하여 저장 공간을 줄이고, 네트워크를 통한 전송을 용이하게 하는데 목적이 있다. VPCC를 통해 대용량의 3D 데이터를 더 작은 크기로 변환할 수 있다.