Preliminary Development Plan


- CfP(Call for Papers) Results
: 총 4개의 기관에서 proposals이 제출되었고 apple의 기술이 채택되었음.
///CfP란..Call for papers의 약자로, 학술대회나 저널,워크샵,심포지엄 등에서 연구자들을 대상으로 논문 제출을 요청하는 공고를 말한다.
- Adopt P11(Apple) 간단 소개
: initial mesh의 simpified version을 먼저 간단하게 보내주고, 원본 mesh와 simplified version mesh의 차분값을 전송해주는 scalable 코딩방식을 채택했다.
scalable coding 으로 mesh의 geometry부를 coding한 후에 attributes쪽texture map과 displacement를 2d로 mapping해서 보내주는 방식이다.
All Intra / Random Access
- All Intra (AI) //독립 인코딩
모든 프레임이 독립적으로 encoding되는 방식이다. 즉 각 프레임은 다른 프레임으로부터 참조 없이 자체적으로 압축된다.
장점 : 빠른 random access와 편집이 가능하다. / 오류 전파 x
개별 프레임이 독립적이기 때문에, 특정 프레임으로 바로 접근하거나 비디오를 편집하기에 용이하고,
한 프레임에서의 오류가 다른 프레임으로 전파되지 않는다.
단점 : 높은 bitrate
각 프레임을 독립적으로 압축하기 때문에, 다른 프레임과의 차이를 이용한 압축 이점을 얻을 수 없다. 이는 동일한 품질 수준에서 더 높은 bitrate를 요구한다.
- Random Access (RA) //참조 인코딩
Random Access는 I-프레임, P-프레임,B-프레임을 포함한 프레임 간 참조를 사용하여 encoding한다.
RA 모드는 특정 프레임 (보통 I-프레임)에서만 random access를 허용하며, 다른 프레임들은 I-프레임과 다른 참조 프레임들을 기반으로 예측된다.
장점 : 효율적인 압축
프레임간의 상관관계를 이용하여 비디오를 더 효율적으로 압축하므로 더 낮은 bitrate로도 더 높은 품질의 비디오를 저장할 수 있다.
단점 : random access 제한, 오류 전파 0
I-프레임에만 제한적으로 random access가 가능하므로, 다른 프레임들에 바로 점프하여 디코딩하는 것이 복잡하다. 또한, I-프레임이 나머지 프레임들과 참조 관계가 있기 때문에 I-프레임 및 참조 프레임이이 갖는 오류를 다른 프레임에 전파시킬 수 있다.
V-DMC CfP results
- PSNR ( Peak Signal to Noise Ratio )
: 영상 처리 분야에서, 원본 영상 대비 압축이나 다른 처리 과정을 거친 영상의 손실 정도를 객관적으로 비교하는 데 자주 사용된다. PSNR은 두 영상 간의 차이를 나타내는 지표로, 값이 높을수록 두 영상 간의 차이가 적다는 것을 의미하며, 이는 보통 높은 영상 품질을 나타낸다.
영상 품질을 평가할 때에, 압축 효율성(bitrate)과 품질(psnr)을 동시에 평가하기 위해 bitrate와 psnr을 지표로 사용한다.
(Objective quality comparsion)- AI(All intra) configuration
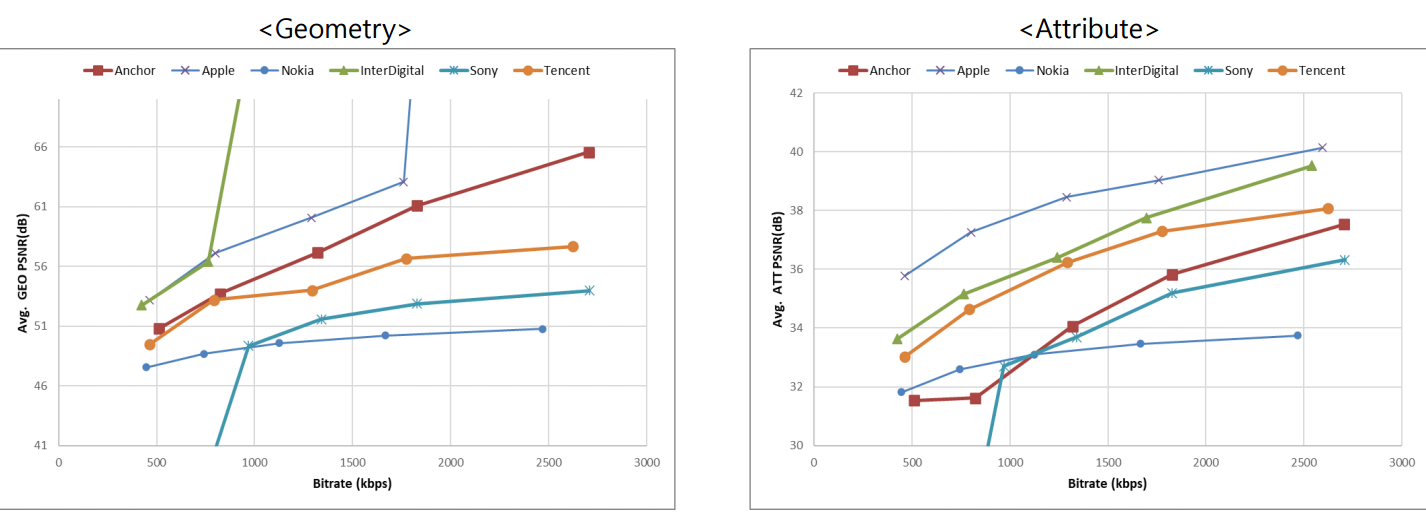
(Objective quality comparsion)- RA(random access) configuration
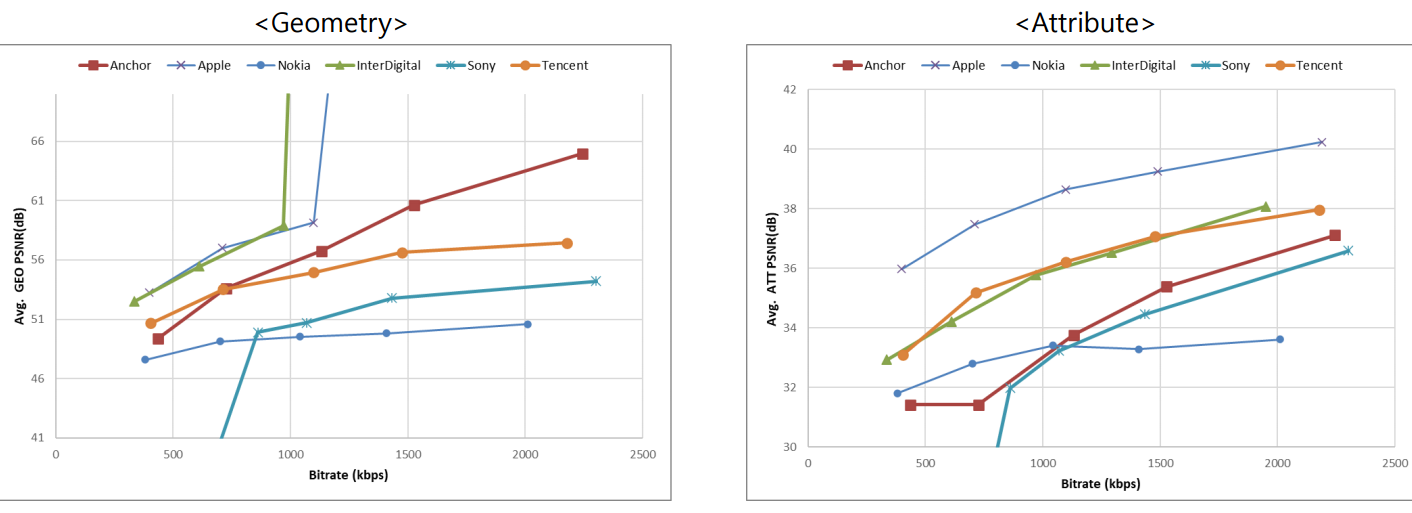
apple이 attribute에서 좋은 성능을 보인 이유는 pre-processing 과정에서 mapping을 잘 해주는 기술이 들어가 있어서....
(Subjective quality test )

움직이는 물체에 대해서 다음과 같이 camera path를 두고 Rendering을 진행하여 MOS test를 했다.
*** MOS Test
: Mean Opinion Score Test의 약자로 주로 오디오,비디오의 시스템 품질 평가에 사용되는 주관적인 평가 방법이다.
MOS는 사람들이 제공하는 피드백을 기반으로 하며, 서비스나 제품의 품질을 수치화하여 나타낸다.
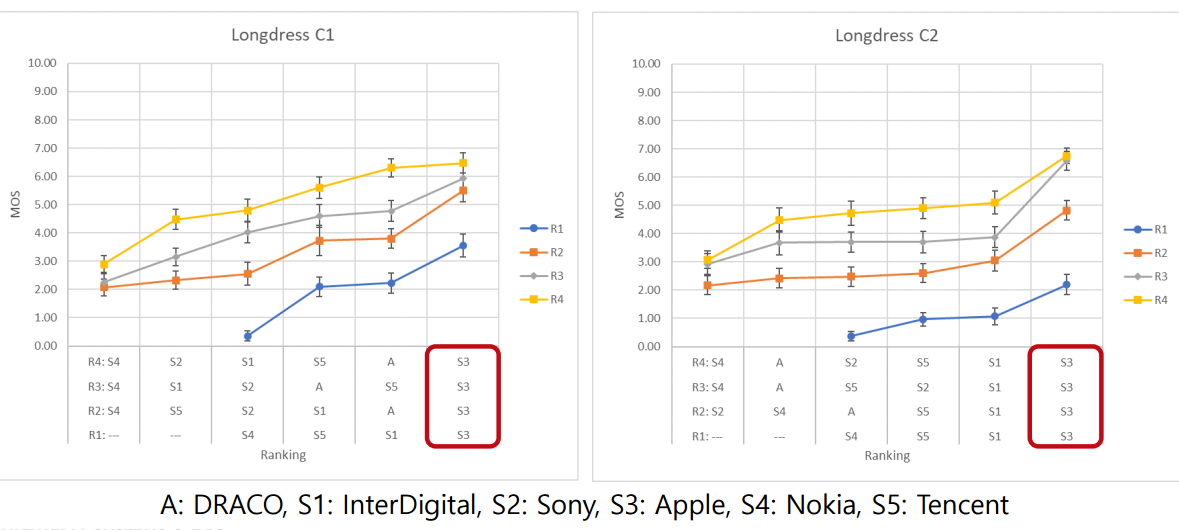
S3(Apple)의 기술이 가장 높은 mos가 나와서 apple이 CfP의 winner가 되어쑴~ 추카추
V-DMC Test Mode "TMMv1"
: apple의 기술을 기반으로 test model인 TMM version1을 만들게 되었다.
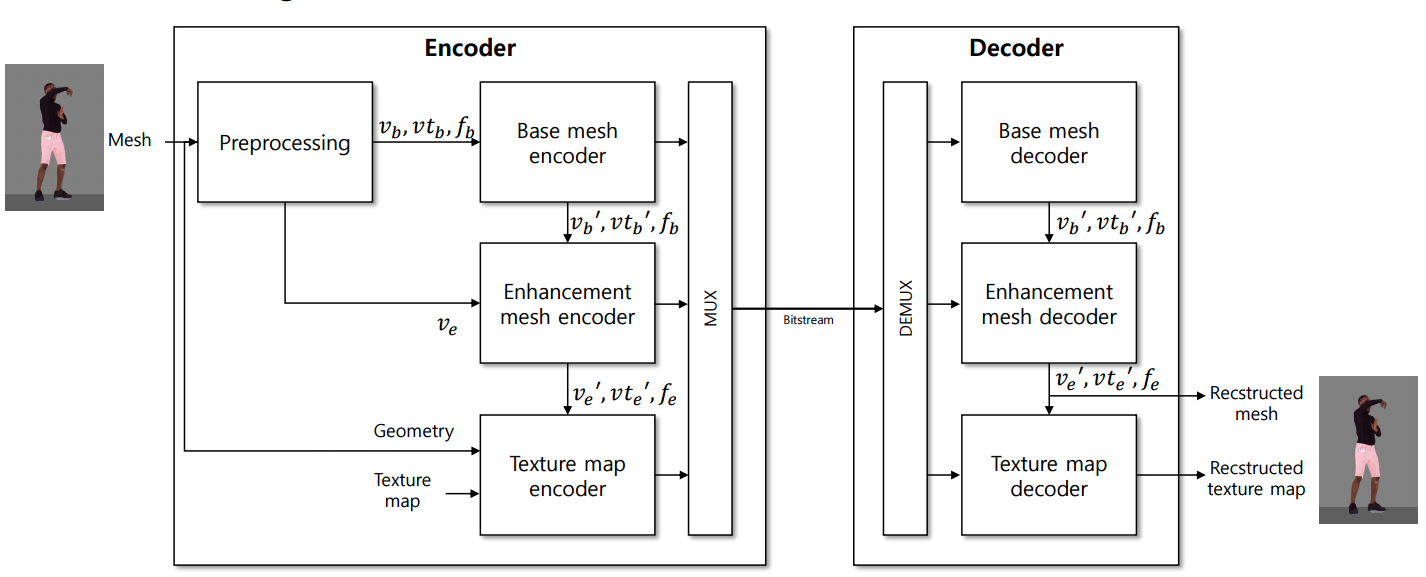
[ Encoding ]
Preprocessing (전처리)
: 입력으로 mesh를 받으면 잘 coding할 수 있는 데이터 형태로 전처리를 한다.
Base mesh encoder
: mesh의 기본 구조를 인코딩한다. 이는 mesh의 기본 형태를 나타내는 vertex(점,Vb), texture coordinates(vtb), face(면,fb) 정보를 인코딩한다. 이 단계에서는 상대적으로 저해상도의 형태로 압축된다.
Enhancement mesh encoder
: base mesh에 더 세밀한 디테일을 추가한다. 전처리에서 나온 고해상도의 vertex(Ve)와 texture coordinates, face 정보가 포함된다. 이렇게 함으로써 보다 정밀한 mesh details를 복원할 수 있다.
=> Base mesh와 enhancement mesh 두 개의 구조가 scalable구조를 가지고 있다.
Texture map encoder
: 메시의 texture 정보를 인코딩한다. texture는 3D 객체의 표면에 적용되는 이미지나 패턴으로, 객체에 색상, 재질 느낌 등을 부여한다.
Muxing (멀티플렉싱)
: 모든 인코딩된 data stream을 하나의 bitstream으로 결합한다. 이 과정을 통해 모든 데이터가 통합되어, decoding과정에서 각 요소를 동기화하여 복원할 수 있게 된다.
Bitstream
: 최종적으로 생성된 비트스트림은 전송이나 저장을 위해 사용된다.
??mux로 하나로 나가되, bitstream에 누적되어 전달되는건가?
=> 이러한 방식은 데이터를 효율적으로 압축하면서도 복원시 높은 품질을 유지할 수 있다.
[ Decoding ]
Base Mesh Decoder
: 비트스트림에서 base(기본) mesh 정보를 추출하여 디코딩한다. 이는 정점(vertex, 'vb′), 텍스처 좌표(texture coordinates, ′vtb′), 면(face, ′fb′) 데이터로 구성되어 있으며, 메시의 기본 형태를 복원하는 데 사용된다.
Enhancement Mesh Decoder
: 비트스트림에서 추가적인 메시 세부 정보를 디코딩하여 base mesh에 적용합니다. 이 과정은 메시의 정밀도를 높이며, 고해상도의 정점(vertex, ′ve′), 텍스처 좌표(texture coordinates, ′vte′), 면(face, ′fe′) 정보를 포함할 수 있습니다.
Texture Map Decoder
: 비트스트림에서 texture map 정보를 디코딩합니다.
이 단계는 3D 메시에 적용될 texture image를 복원하는 데 사용됩니다.
Demuxing
: 인코딩 과정에서 결합된 비트스트림을 다시 각각의 구성 요소로 분리합니다. 이는 디코딩 과정에서 각 요소가 별도로 처리될 수 있도록 합니다.
Reconstructed Mesh
: 기본 메시와 개선 메시 정보를 결합하여 최종적으로 높은 정밀도의 3D 메시를 복원합니다.
Reconstructed Texture Map (재구성된 텍스처 맵)
: 디코딩된 텍스처 맵을 최종 3D 메시에 매핑하여, 메시의 외관을 복원합니다.
이는 색상, 패턴, 재질 등을 메시에 적용하는 과정입니다.
=> 디코딩 과정은 인코딩 과정의 역순으로 이루어지며, 최종적으로 사용자가 3D 모델을 시각적으로 인식할 수 있는 형태로 데이터를 복원하는 것을 목표로 합니다.
왜 base mesh와 enhancement mesh 모두 다룰까?
1. Multi-level details (LOD: level of Detail)
: base mesh는 기본적인 구조의 저해상도 mesh, enhacement mesh는 세부사항이 더해진 고해상도 mesh이다. 이러한 multi level detail은 사용자가 서로 다른 품질 수준을 선택할 수 있게 하거나, 네트워크 속도나 기기 성능에 따라 동적으로 조정될 수 있는 스트리밍을 가능하게 한다.
=> Scalability : multi level encoding은 scalabe video coding(SVC)와 유사한 개념으로, 다양한 품질 또는 해상도 level을 지원하여, 사용자의 요구사항 및 네트워크 상황에 맞는 콘텐츠로 조정할 수 있도록 한다.
2.효율적 압축
: base mesh를 통해 주요 형상 정보를 먼저 전송하고, enhancement mesh를 통해 세부사항을 전송함으로써, bandwidth가 제한적인 환경에서 유용하게 쓰일 수 있도록 한다.
3. 점진적 전송과 rendering
: 저해상도부터 고해상도로 점진적으로 모델을 전송하고 rendering함으로써, 사용자는 모델이 완성되기 전에 모델의 초기 형태를 볼 수 있게 된다. //base 정보로 미리 보여주는 건가//
4. error 복원력
: base mesh와 enhancement mesh가 서로 분리된 layer에서 인코딩 되기 때문에, 전송 과정 중에 error가 발생했을 때, 서로에게 주는 영향이 적다. 즉, 에러가 발생하더라도 에러가 발생하지 않은 다른 layer를 통한 값을 통해 복원을 해낼 회복력을 가지도록 설계되었다는 의미를 가진다.