Extracting Motion and Appearance via Inter-Frame Attention
for Efficient Video Frame Interpolation
Methods

EMA의 전체 아키텍처 구조는 위와 같다.
time 0과 1 사이 t에서의 frame을 생성하는 것이 목적이다. 위 식에서 It hat이 generated frame이다.
*** O: proposed model
low-level Feature Extractor
입력 프레임의 해상도가 높을 경우, inter frame attention에서 attention map을 생성하는 데에 큰 메모리 사용이 필요하고, 계산 부하가 생길 수 있으므로, 이러한 문제를 해결하기 위해, CNN으로 이루어진 low level feature extractor를 활용한다.
low level featuer extractor는 여러 CNN layer로 이루어져 있으며, 단일 Frame의 Appearance 외관 특징을 다양한 scale로 추출하는데 사용된다.
위 식은 i번째 프레임을 low level feature extractor에 넣으면 3가지 scale에서의 feature가 생성된다는 것을 표현한다.
( 여기서 구해진 appearance 를 바탕으로 이후에 나오는 VIT에서 attention 연산이 이루어진다.
그리고, 그렇게 구해진 attention map으로 enhanced appearance와 motion vector를 구해낸다. )
down sampling 될수록 channel의 수는 2배가 된다. 따라서 위와 같은 shape이 만들어진다.
[ hybrid 구조의 한계 ]
이렇게 CNN을 먼저 처리함으로써, 연산 부담을 줄였으나, 이로인해 transformer가 받을 input에 대한 세밀한 정보가 부족해지는 문제가 발생한다.
이를 해결하기 위해 Cross-scale patch embedding을 추가하여, CNN에서 나온 feature들을 재사용하여 cross-scale 정보를 보완한다.
[56]에언급된 multi scale dilated convolution을 사용하여 feature들의 정보를 혼합하는 것을 제안한다.
3.1 Extract Motion and appearance information
Attention Map
[Figure2]

I0 프레임의 임의의 영역 i,j를 A0(i,j)라 하고, I1프레임의 i,j에 대한 이웃 영역들을 A1(ni,j)라 하자.
I0의 임의 영역을 query로 사용하고, 이에 대한 공간적 이웃 거리에 있는 임의 영역 A1(Appearance)들을 query와 value로 사용한다.


단, A0,A1(Appearance)를 query,key,value로 사용하려면 multi head attention에 들어가기 전에 input을 통일시켜줘야하기 때문에 위와 같이 matrix와의 곱으로 값들의 차원을 맞춰주어 Q0,K1,V1의 형태로 만들어준다.
Q0와 K1과의 dot product 연산을 통해 유사도를 구하고,

softmax를 취해 가중치르 구한 다음 이를 value값에 곱하여 모두 합하면 attention map(S0->1)이 생성된다.
attention map은 본래 transformer 구조대로 query와 key의 유사도를 기반으로 생성된다.
즉 현재 바라보고 있는 i,j위치에 대한 I0에서의 일부 영역과 I1프레임에서의 그 주변 영역들에 대해 유사도(상관 관계)를 분석하는 것이다.
이렇게 만든 attention map을 통해, I0과 I1의 appearance 정보를 통합하고, I0에서의 I1으로의 대략적인 motion vector(M0->1)를 추정할 수 있다.
위 예시를 보니, 자동차가 나온 I0 프레임에 대해 I1에서의 이웃한 영역들 9개에 대해 바라보는 것이다
I1에서 자동차가 있는 부분에서는 attention 값의 높게 나온 것을 확인할 수 있다.

Inter frame attention에서 (a)에서 설명한 연산을 통해 attention map이 형성된다.
*** attention map : query와 key의 유사도 확률값
이렇게 생성된 attention map은 appearance 정보를 전송하고, motion 정보를 얻는데에 동시에 활용된다.
Appearnce 정보
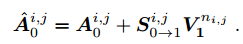
유사도 확률값과 value를 곱한 값을 I0 의 i,j영역의 appearance에 더하여 두 프레임 간의 상관관계를 반영하여 다음 프레임에도 나오는 영역에 대한 값을 더욱 강조하는 효과를 주어 I0 프레임을 더욱 enhance한다.
즉 연속되는 프레임 사이의 시각적 일관성을 높이는 데 사용된다.
또한, Frame Interpolation에서 I0과 I1 사이의 frame의 appearance를 예측할 때, 두 프레임의 appearance를 혼합한 정보를 사용함으로서 더 정밀한 appearnace를 생성할 수 있다.
Motion 정보

s가 1이라 가정 ,, (가정) // 디지털 영상 처리 좌표계 기준으로 생각하기
(3,0) -(0,3)= (3,-3)

Motion vector는 좌표를 바탕으로 정해진다. attention map을 통해 얻은 유사도 확률만큼만 I1프레임의 좌표값을 반영하여 Motion vector를 얻을 수 있다.
Motion feature는 이러한 Motion vector와의 Linear 연산으로 아래와 같이 구해질 수 있다.

trained model에 의해 estimated optical flow와 motion vector를 비교하면, 두 프레임의 동일 영역에 대해 유사성을 파악할 수 있다.
