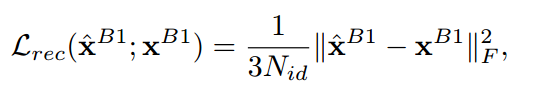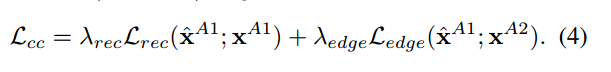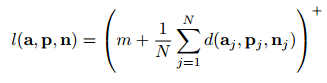3D pose transfer는 source의 pose를 target의 geometry에 전달해서 대상의 identity를 유지하며 pose만 바꾸는 것을 목표로 하는 "생성 작업"이다.
이전 방법들은 source와 target의 correspondence를 찾기 위해 key point 주석을 필요로 한다. ( input으로 주어지는 두 mesh외로 추가적인 정보가 필요하다는 뜻 )
#supervised learning
현재 pose transfer 방법은 end-to-end correspondence learning을 허용하나,
desired final output을 supervision의 ground truth로서 필요로한다.
*** desried final output : 모델이 생성해야하는 목표 출력 ( source의 pose를 target에 전달한 결과물)
즉, 모델을 training시킬 때 target pos에 대해 기대되는 결과값(gt)이 제공되어야한다는 것
#unsupervised leanring
source와 target 사이 ground truth correspondence를 요구해서 탈락
#proposed
따라서!
correspondece label 없이, ( 즉 model이 source와 target 간의 정확한 대응을 알지 못한 상태로 학습 )
unsupervised,semi-supervised,fully supervised setting에서 train될 수 있는
novel self-supervised framework를 제안한다. ( 즉, 다양한 학습 환경에서 작동할 수 있는 )
correspondece를 필요로 하지 않음으로서 , 데이터 준비 과정에서의 복잡성을 줄이고, 다양한 데이터셋이 적용할 수 있는 가능성을 열어준다.
- unsupervised learning : 모델이 입력 데이터만 받고 ground truth나 correspondence 정보 없이 스스로 학습한다. 숨겨진 패턴이나 구조를 발견하며, 모델이 자체적인 기준을 사용해 학습 수행 정도를 판단한다.
- Semi-supervised Learning : 일부 데이터만 ground truth을 가지고 있으며 나머지 데이터는 ground truth 없다. 즉, label이 있는 데이터를 사용하여 학습하는 동시에, label이 없는 데이터에서도 패턴을 학습하려고 시도한다.
- Fully Supervised learning : 모든 학습 데이터가 그에 해당하는 ground truth를 가지고 있다. 가장 빠르과 효과적인 학습 결과를 제공한다.
#Learning constarints
: loss함수가 학습과정에 제약을 부과하므로 loss에 대한 정보를 이렇게 표현
1. Mesh-level loss for disentangling global patterns including pose and identity :전체 mesh의 특징을 pose와 identity로 나누어 이해하는 것에 대한 mesh 단위의 loss
2. pont-level loss for discriminating local semantics : mesh의 개별 point 단위에서 작동하며, 더 세밀한 지역적 특성의 의미를 파악하는 데 사용된다. 즉, mesh의 각 point들이 주변에 있는 point들과 어떻게 다른지를 판단 //local semantics 구별에 이용되는 loss
그럼 이 model은 mesh단위로도 학습을 하고, point 단위로도 학습을 한다는거네
*** state-of-the-art : 최신 기술
introduction
# Challenges of 3D pose transfer
- Correspondence label의 필요성 : 현재 많은 3D pose transfer 방법들은 두 input 간의 쌍 즉, correspondence labels를 필요로 한다. 이는 모델의 한 점이 다른 모델의 어느 점에 해당하는지를 알려주는 정보이다. ground truth correspondence를 수집하고 레이블링하는 과정은 3D pose 전송 모델을 효과적으로 훈련시키기 위해서는 필수적이지만, 학습 데이터를 준비하는 과정에 너무 큰 노력이 필요하다.
- 다른 연구 사례 [33] : optimal transport를 기반으로 한 correspondence moduel학습 방법을 제안했으나, 이는 supervised learning으로, ground truth를 필요로 한다. 이는 data set에 대해 너무 많은 요구를 필요로 하기에 실용성이 떨어진다. // target output인 gt는 필요로 하나, correpondence label은 필요로 하지 않는 model
[47] : Graph Convolution network와 ARAP변형을 기반으로 하며, gt correspondence가 필요함...!
즉, correspondence label이 필요하나, 그것을 만드는 것이 어려운 게 문제임
# Propose
위에서 언급한 loss로 Mesh and point contrastive learning을 활용한 3D pose 전송을 위한 self supervised framwork인 MAPConNEt을 제안한다.
MAPConNet은 correspondence label이나, ground truth(목표 출력물)을 필요로 하지 않으며,
supervised, unsupervised, semi-supervised에 모두 적용할 수 있다.
또한, source 와 target이 같은 순서의 점을 갖거나, 같은 수의 점을 가질 필요가 없다.
[47]의 unsupervised-learning 접근법을 unaligned mesh에 대한 pose transfer에 적용할 것이며,
[33]을 base line으로 한다.
- disentanglement unsupervised-learning에서 데이터의 중요한 특징을 파악하고 이해하는 과정 없이 데이터의 오류나 특정만에 의존하여, 복잡한 학습과정을 건너뛰고 shortcut(단축경로)를 찾아내는 것을 막기 위하여 pose와 latent에 대해 latent pose와 identity representations을 분리한다. (disentanglement) // pose와 identity에 대해 각각 고려하지 못하고, 서로를 noise로 생각해버리는 경우가 있을 수도 있으므로
- mesh level contrasitve learning : model의 중간 output이 (respective) input의 latent pose와 identity에 더 잘 맞게 하는 학습
- point-level contrastive learning : model의 중간 output뿐만 아니라, correspondence module의 qualtiy도 좋게 하기 위해서, correspondence 점들의 표현에는 유사성을 더욱 강조하고, non-correspondence 점들 사이에는 비유사성을 더욱 강조하는 대조 학습을 진행한다. -> 더 정확한 분류를 유
** contrastive learning : 대응하는 점들은 비슷한 표현을 갖도록 하고, 대응하지 않는 점들은 다른 표현을 갖도록 학습하는 방
Methodology
#connectivity
x A1 ∈ R Npose×3 는 Npose개의 점의 개수를 가진 3차원 공간에서의 점들의 집합을 의미한다. (Nx3행렬이다)
-> 3차원 아님 주의 N개의 vertex들에 대해서 각 행에 x,y,z 위치 표시
제안된 model에서 mesh는 point-clouds로 처리되지만, 훈련을 위해서는 connectivity가 필요하다.
#input/output order
input으로 들어오는 두 mesh에 대해서는 vertices의 동일한 순서를 요구하지 않지만,
output mesh는 target mesh와 동일한 order를 가져야한다.
*** 순서가 왜 필요 ? : point 는 각각으로 존재하지만 이 데이터가 처리될 때에는 일련의 순서를 갖고 나열되니까
# Optimal transport matirx (T) T는 optimal transport matrix로 두 input의 latent feature를 기반으로 학습된 matrix이다. 즉, source mesh의 각 point를 target mesh의 point로 얼만큼 이동시킬지(이동하는 비율)를 정량화한 것이다. 따라서, T행렬(이동 비율)과 source mesh의 vertex위치를 곱함으로써, source의 정점이 target의 어느 위치로 이동할지를 계산할 수 있게 되는 것이다.
X는 Nx3 matrix이다. 즉 2차원 행렬이며, N개의 vertex들에대해 각 행에 x,y,z위치 정보를 포함한다. T는 NxN matrix이다. 즉, T 역시 2차원 행렬이며, T와 X를 곱하면 NXN x Nx3 = Nx3의 행태돌 새로운 mesh에 대한 위치데이터 집합이 warped output으로서 나온다.
- Refinement Module refinement module에서 instance normalisation을 통해서 warped output에 대한 style condition으로 target mesh의 identity feature를 사용한다. 그리고 최종적으로 final output이 만들어진다.
여기까지 설명하고 있는 CoreNet의 구조는 supervised구조이므로 gt를 필요로한다. model의 output으로 나온 xhatb1과 실제 gt인 xb2과이 차이로 reconstruction loss를 구한다.
3.2 latent disentanglement of pose and identity ( feature 분해 )
#Supervised pipeline (3.4/3.5)
Lmesh, Lpoint
#Unsupervised (3.3)
self-consistency loss , cross-consistency loss [47]
이러한 loss들을 바로 사용하면, 최적화된 결과를 얻지 못한다.
이유 : baseline인 3D corenet은 latent disentanglement가 없으니까'
그러므로, input mesh의 feature를 pose와 identity에 대한 channel로 나눈다. ( feature disentanglement)
전체 feature의 dimention은 id feature에 대한 dimention과 pose feature에 대한 합이다.
이러한 분리 과정을 거쳐 identity의 feature는 refinement module의 input style condition으로서 사용된다.
//correspondence module에는 identity와 pose에 대한 channel이 모두 들어간다.
Unsupervised pose transfer
!!!!!! CoreNet은 supervised leanirng이라서, 의도된 pose와 identity를 가진 ground truth output을 필요로해 !!!!!!!!
unsupervised pose transfer의 학습 과정에 필요한 training sample 요구사항
1. 동일 identity에 다른 pose
: 같은 개체가 다른 포즈를 취하는 샘플을 수집하는 것
2. 다른 identity의 동일한 pose
: 이 조건은 충족하기 어렵다. 서로 다른 객체가 동일한 포즈를 취해야한다.
unsupervised lenaring의 경우 동일한 identity의 다른 pose만 있으면 pose 전달이 가능하다고 [47]에서 이야기 하고 있다.
# two sub-tasks
unsupervised learning에서의 network는 두 가지 task에 대해 동일한 출력을 내야한다.
(a)두 개의 input의 identitty가 같을 때
(b) a의 pose input(source input)의 identity가 다를 때 //즉 identity는 다르고 pose만 같은 input
(a). cross-consistency //이미 가능한
: 동일한 identity의 다른 pose를 네트워크의 입력으로 제공한다. 여기서 네트워크의 목표는 두 입력이 동일한 신원임을 인식하고, 이를 바탕으로 출력을 생성해야한다.
(b). self-consistency //pose input을 self로 생성..?
: (b)의 상황에서는 pose input ( source input )을 사용할 수가 없지만, network 스스로 pose input을 생성해 낼 수 있다. 이것이 바로 self-consistency이다.
unsupervised의 상황이므로 특정 pose를 다른 identity로 전달하고자 할 때, 해당 target mesh에 대해 실제 그 pose를 취하고 있는 실제 gt를 가지고 있지 않는다. 이러한 상황에서 self-consistency란 네트워크가 스스로 해당 pose의 예시를 생성하여 학습 과정에 사용하는 것을 의미한다.
#vertex 정렬 필요
하지만 [47]의 GCN model과 ARAP deformation은 두 input mesh의 vertex들이 사전에 정렬되어 있어야 한다.
즉, 한 mesh의 i번 째 vertex가 다른 mesh의 i번째 vertex와 대응한다는 것을 의미한다.
-> 그러나!! unsupervised learning을 가능하게 하기 위해
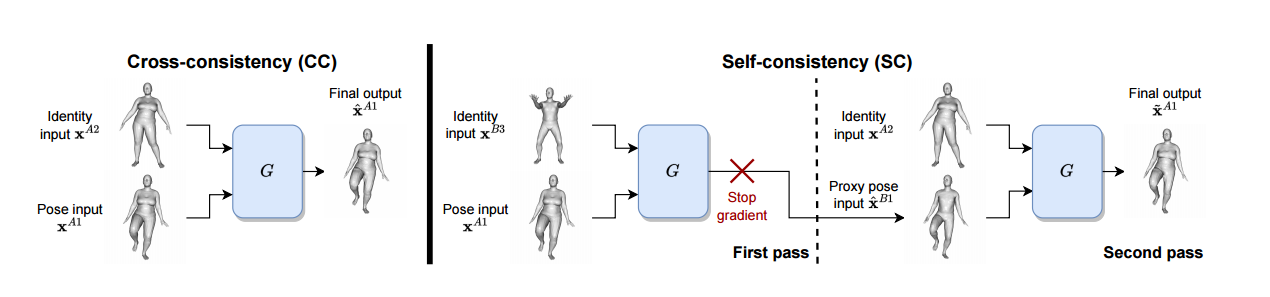
정렬되지 않은 mesh에 대해 cross-consistency와 self-consistency를 합칠 것을 제안한다.
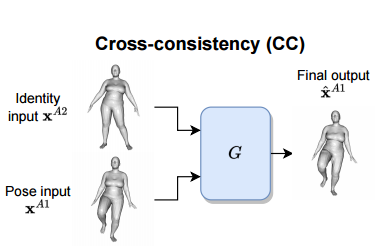
CC ( cross-consistency )
input : identity는 동일하되, pose만 다른 객체
pose input과 identity input는 동일 객체이므로, vertices의 order가 동일해야한다.
단순히 CC만으로는 서로 다른 identity를 가진 mesh 간의 transfer을 수행하기 어렵다.
CC는 동일 identity간의 학습만 진행했기 때문에, 다른 identity를 가진 객체에 대해서는 훈련받지 못했다.
G는 서로 다른 identity의 경우에도 pose를 transfer할 수 있어야한다.
SC에서 [47]은 proxy input을 생성하도록 하였다. 즉, unsupervised 라서 gt가 없는데 identity까지 다르니까 학습에 쓰일 데이터가 부족하므로, network가 자신이 사용할 데이터를 스스로 생성하도록 한 것이다.
*** proxy input : 실제 데이터를 대신해 네트워크에 의해 생성된 가상의 데이터를 의미한다.
즉, network가 직접 자신의 훈련 데이터를 생성하여, 그 데이터를 바탕으로 더 나은 예측 능력을 개발하도록 하는 것이다.
SC는 두 번의 pass 방식으로 진행된다.
1) first pass
: 서로 다른 identity를 가진, pose input과 identity input이 주어지면, 이를 바탕으로 proxy data가 될 녀석을 생성한다.
2) second pass
: proxy data가 pose input으로 사용되고 , cc에서 identity input이었던 것을 그대로 다시 가져와서 network르 거치게 한다.
즉, CC의 과정에 다른 객체에 대한 identity 정보를 한 번 사용하여 두번의 pass를 지나게 한 것이다.
#SG
SG(stop gradient)는 model이 shortcuts를 찾아버리기 위해
첫번째 pass에서의 A1을 두번째 pass에서도 직접 사용하는 것을 막기 위함이다.
즉, 모델이 너무 쉽게 문제를 해결하거나 훈련 데이터에 과도하게 의존하여 일반화 능력이 떨어지는 것을 막기 위함이다.
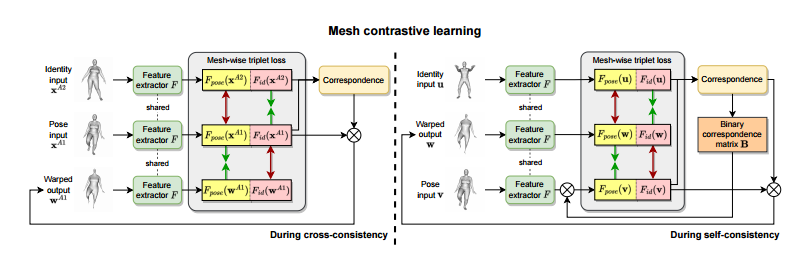
3.4 Mesh Contrastive Learning
3.2절에서 언급한것처럼 이 모델에서 latent feature를 pose에 대한 feature와 id에 대한 feature로 분리하였다.
이를 통해 model output의 정확도가 더 높아진다.
예를 들어 pose와 identity의 측면에서 각각 입력과 출력을 비교하고, consistency 유지를 위한 loss를 부과한다.
또한, unsupervised learning에서 일어날 수 있는 shortcut을 latent space의 분리를 통해서 방지한다.
-> unsupervised에서 shortcut 찾다가 pose와 identity에 대해 각각 고려하지 못하고, 서로를 noise로 생각해버리는 경우가 있을 수도 있으므로..?
pose와 identity에 대한 mesh level contrastive learning loss를 제안한다.
mesh 공간에서는 pose와 identity를 직접적으로 비교할 수가 없기 때문에, 우리는 self-supervised approach를 취한다.
self-supervised learning에서는 label이 명시적으로 제공되지 않지만, 데이터 자체에서 학습에 사용될 정보를 추출할 수는 있다. - Feature Extractor F에 mesh를 입력하여 latent representation을 생성한다. - triplet loss라는 특정 손실 함수를 latent representation에 적용한다.
[triplet loss] //vertex들에 대한 latent 표 : 학습 과정에서 세 개의 샘플을 비교하는데 사용되는 loss함수이다. 이 세개의 샘플은 anchor,positive,negative 샘플로 구성된다. anchor : 기준이 되는 샘플 positive : 앵커와 같은 카테고리(identity,labe등)에 속하는 샘플 negative: 앵커와 다른 카테고리에 속하는 샘플 -> triplet loss이 목적은 anchor와 positive 간의 거리는 최소화하고, negative 와의 거리는 최대화하는
정렬된 mesh에 대해서 계산 가능한 pose나 identity에 대한 latent 표현에 대한 거리들의 평균에 margin을 더한것 중 최고가 loss가 된다.
ex ) 예를 들어 identity에 대해 다룰 때에는 target mesh와 warped mesh가 각각 앵커 표현과 긍정 표현이 되어 둘의 거리는 가깝고, source mesh의 identity는 부정표현이 되어 거리가 최대화되도록 하는 것같군!
pose에 대한 triplet loss는 그 반대의 경우일거고!
### Contrastive learning in CC
CC는 동일 identity에 대한 다른 pose에 대한 출력을 예측하려고 시도한다.
1. Xa1과 Xa2가 주어졌을 때 Wa1(warped mesh)를 출력해내야한다.
직관적으로 Xa1의의 pose 표현은 Wa1의 포즈 표현과 더 일치해야한다. ( Xa1의 포즈를 Wa1에 상속하는 거니까)
2. CC에서 2개의 input과 최종 output은 모두 동일한 identity를 가지고 있어야하지만,
Xa1은 identity representation 은 Xa2와 비스해야한다. Wa1보다는..!
Wa1은 pose input으로부터 identity representation을 상속받는 것을 피하고, pose정보만 가져오도록 했기 때문에
2가지 이유 때문에 final output대신에 warped output을 사용한다.
1. warped output을 사용하는 것이 원하는 최종 출력에 더 가깝게 refinement하기 쉽다 2. refinement module을 포함하지 않기 때문에 computational cost가 낮다.
-> 일단 CC에서는 이 루프로 학습을 진행하고 refinement는 나중에 최종 output쪽에 있는 거일수도 있겠다....!
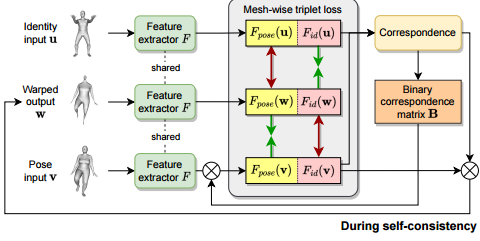
### Contrastive learning in SC
SC에서는 2개의 연속된 pass를 거쳐 결국엔 CC와 동일한 output을 만들어야한다.
CC와 다르게, u와 v의 (아래그림 참조) vertex order가 정렬되어있지 않는다. (identity가 다른 객체니까)
그 결과,
Point Contrastive Learning
### mesh contrastive loss와 point contrasitve loss에 대한 비교
첫 번째 사진에 나와 있는 식은 메시의 잠재 표현에 대한 트리플렛 손실을 나타내고 있고, 여기서는 메시 전체에 대한 손실을 계산하기 위해 메시를 구성하는 각 포인트의 잠재 표현을 평균화하는 것을 보여줍니다. 즉, 여기서는 메시를 구성하는 모든 포인트를 통틀어 메시 수준에서의 손실을 계산합니다. 두 번째 사진에 나와 있는 식은 포인트 레벨에서 대조 학습을 위한 트리플렛 손실을 보여주고 있습니다. 이 식에서는 각각의 포인트에 대해 개별적으로 손실을 계산하며, 이는 메시의 개별 포인트들이 서로 얼마나 유사한지 또는 서로 다른지에 대한 손실을 나타냅니다. 두 접근법의 차이점은 범위와 초점에 있습니다: - 첫 번째 사진의 메시 대조 학습에서는 메시 전체의 특성을 평균화하여 대조 손실을 계산합니다. 이는 메시 전체의 포즈나 신원 특성을 나타내는 잠재 표현의 유사성을 강조합니다. - 두 번째 사진의 포인트 대조 학습에서는 각각의 포인트에 대해 독립적인 대조 손실을 계산합니다. 이는 메시의 세부적인 특성과 구조를 더 잘 이해하고 강조하는데 유리합니다. 두 방식은 각각 메시와 포인트 레벨에서의 학습을 목표로 하며, 특정 연구의 목적과 맥락에 따라 적절히 선택되어 사용됩니다. 제가 이전의 대화에서 '메시' 대신 '포인트'라는 용어를 사용한 것은 오해를 불러일으킬 수 있는데, 분명히 해야 할 점은 메시 대조 학습은 메시 전체의 특성을 고려하며, 포인트 대조 학습은 메시를 구성하는 각각의 포인트를 독립적으로 고려합니다.