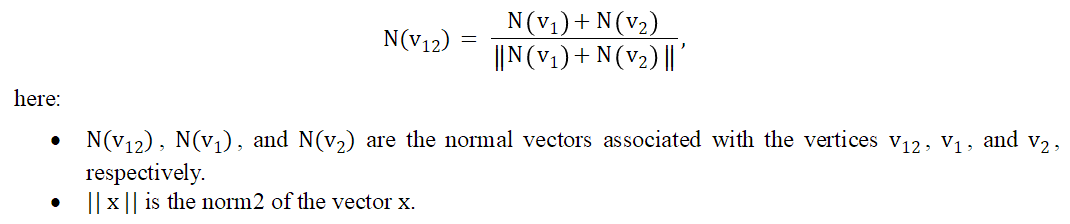: intra mode는 모든 frame에 대해 독립적으로 압축되어 다른 프레임의 참조를 필요로 하지 않는다.
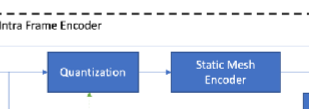
2.2.1 Base Mesh Encoding
- Quantization & Encoding (with Draco Codec)
: current frame에 대한 base mesh m(i)가 먼저 quantization되고, 그 다음에 static mesh encoder를 통해서 encoding된다. Proposed scheme는 base mesh를 압축하는데 쓰이는 mesh encoding scheme을 구체적으로 지정해놓지는 않는다. mesh에 대한 codec은 bitstream에서 명시적으로 지정되거나, 사양이나 애플리케이션에 의해 암시적으로 정해질 수 있다. CfP(Call for Proposals)에 대한 결과는 Draco mesh Codec을 기반으로 한다.
: base mesh에 대해 압축된 결과가 1차적으로 mux에 전달된 후, 다음 처리를 위해서는 encoding된 mesh를 다시 decoding하여 다룬다.
Quantization은 정보량을 줄이되, 손실은 무조건 발생하는 손실 압축이기 때문에, m(i)가 그대로 전달되는 것이 아니라, m(i)에 대한 reconstruccted quantized version으로 m'(i)으로 계산된다.
만약 lossless 인코딩을 원한다면, quantization 단계를 skip하고, 이럴경우 m(i)=m'(i)가 된다.
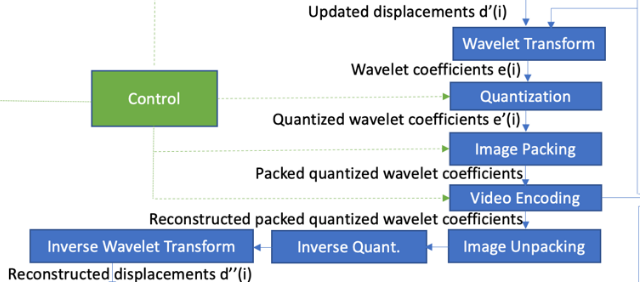
2.2.2 Displacements Encoding
//corse한 data를 base encoding 결과로 빼내어 보내주었으므로, displacements encoding에서는 detail한 부분을 살려준다.
- Update Displacements
: target으로 하는 bitrate / visual quality에 따라, encoder는 subdivision된 mesh vertex들과 연관된 displacement field d(i)를 선택적으로 인코딩할 수 있다.
*** displacement field : d(i) *** reconstructed base mesh : m'(i) //quantization 때문에 바뀐 base mesh..
먼저, reconstructed base mesh m’(i)는 d(i)를 업데이트하여 업데이트된 변위 필드 d’(i)를 생성하는 데 사용된다. 이 과정은 quantization에 의해 재구성된 base mesh m’(i)와 원본 base mesh m(i) 사이의 차이를 고려한다.
// quantization으로 인하여 바뀐 base mesh m'(i) 기반으로 변위 필드도 update하여 d'(i)를 생성 // input으로 들어오는 건 m(i)와의 차이값이니까 quantization 된 m'(i)와의 차이값으로 바꿔야함 // displacements는 subdivision된 거 기준으로 차이값 구했던 거니까 // update displacements module 내에 subdivision 과정이 포함되어 있을 것
-> input으로 주어지는 displacements는 base mesh에 대한 차이값이니까, quantization,encoding을 통해 약간 손실된 reconstructed quantized base mesh에 맞추어서 base mesh와 recon- base mesh의 차이를 displacement에도 반영을 해줘서 displacements를 update해주어야 한다.
- Wavelet Transform & Quantization & Image Packing -> Encoding해서 전달 그리고 inverse..!
subdivision surface mesh structure(2.2.3)를 활용함으로써, //윗 module에서 subdivision된 mesh를 사용하여 그 다음에는 d’(i)에 wavelet transform을 적용하고(2.2.4) wavelet coefficients set가 생성된다. //mesh에 대해서 주파수 domain으로 변환 //geometry 정보에 대해서 residual값들과 DC 값으로 만들기
identity transform을 포함하여 다른 변환을 활용할 수 있다. //wavelet transform이 아니더라도 압축 효율을 높아지게 하는 다른 transform을 사용할 수 있음
그 다음에 Wavelet Coefficients는 Quantization되고, 2D 이미지/비디오로 Packing되며, 전통적인 이미지/비디오 인코더를 사용하여 압축될 수 있다. (V-PCC와 같은 방식으로) //삭제됨..? //원래 3D mesh 였던 걸 2d image로 처리할 수 있도록 packing함으로써 비디오 코덱 사용할 수 있게됨
Video Encoding 결과를 mux로 일단 보내고, Wavelet coefficients의 reconstructed version은 비디오 인코딩 과정 중에 생성된 재구성된 웨이브렛 계수 비디오에 이미지 언패킹과 역 양자화를 적용함으로써 얻어진다. 그 다음 재구성된 변위 d’’(i)는 재구성된 웨이브렛 계수에 역 웨이브렛 변환을 적용함으로써 계산된다.
//encoding 결과를 mux로 보내고 이를 다시 image unpacking하여 2D 형태에서 다시 3d mesh 형태로 바꾸어주고 inverse quant를 하여 quantization되기 전 상태의 wavelet으로 바꾸어주고 이를 다시 inverse wavelet transform을 해주어 displacements값 되찾기...?ㅋㅎㅋㅎ.
//encoding해서 mux 보내려고 wavelet,quant,packing까지 해서 encoding해서 보내고 그거 다시 풀어줌
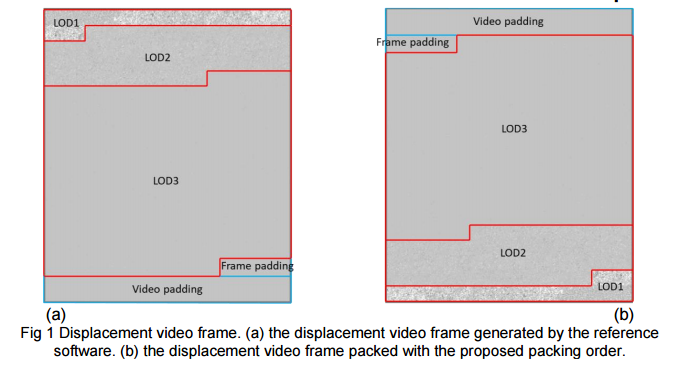
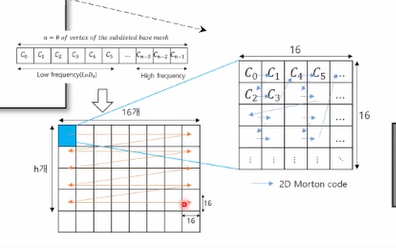
- Image Packing 보충 설명 The Reverse Morton order is used to pacek the displacement coefficients : 위 그림은 displacements가 2D로 packing되는 과정을 보여주고 있다. 10bits binary로 표현되어 1024까지 표현가능하나, default로는 512((회색)를 갖고있다. 값이 커질수록 흰색으로 보여진다.
LOD1 : subdivision이 수행되지 않은 base mesh와 original과의 차이값이다. subdivision을 하지 않고 바로 차이를 구하면 차이값이 크므로 큰 값을 가지는 흰 부분이 보이는 것을 확인할 수 있다. // vertex 개수가 차이가 많이날텐데 이거에 대한 조정은 어디에서 해주지?? LOD2 : subdivision을 1번 해준 base mesh와 original mesh와의 차이이다. LOD2보다 더 작은 차이값을 가지는 것을 확인할 수 있다. LOD3 : subdivision을 2번 해준 base mesh와 original mesh와의 차이이다.
이렇게 0번,1번,2번 subdivision된 mesh들과의 displacements을 차례로 늘여놓아 2D로 packing을 진행한다. //어디가 고주파고 어디가 저주파??
##### 여기서부터는 영상 기준으로 설명한 것 ###### update displacements ~ 끝까지
input으로 enhancement mesh와 reconstructed base mesh를 넣어주고 이에 대한 차를 구하여 displacements를 구한다. //영상에서 이렇게 설명하지만 mpeg 알고리즘에서는 displacements가 preprocessing에서 계산돼서 전달됨
[ Global local coordinate conversion ] displacements encoding 과정을 시작할 때, normal vector값 기준으로 좌표계를 다시 설정해주는 local coordinate conversion을 진행한다.
jpeg에서 크로마 다운 샘플링으로 RGB를 YUV로 바꾸고, Y성분은 살리고 UV 부분은 down sampling한다. 여기서 아이디어를 얻어 Y성분 살리듯이 normal vector 영역의 중요도를 높이고, UV 부분 down sampling하듯이 tangential 영역의 중요도는 낮추도록 local corrdinate conversion을 진행하였다.
[ Lifting Transform ] : wavelet transform의 일종으로 displacements를 frequency domain으로 변경한다. split 되면서 residual값들만 계속해서 나오고 마지막으로 LOD0''까지 나오면 다음 단계로 넘어가 quant된다.
참고 => https://kycu-sb.tistory.com/193
[ Quantization ] : residual 값들과 LOD0''(가장 base 값)을 quantization한다.
[ Image Packing ] :
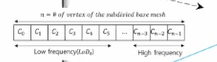
low frequency부터 high frequency까지 쭉 놓고
zigzag같은 morton code order 방식으로 image packing을 해준다.
16x16 block 단위로 morton code packing을 하여 하나의 이미지에 대해 여러 block으로 표현을 한다.
[video encoder] : local coordinate conversion으로 mesh를 normal,tangential domain으로 바꾸어주었으므로, 이를 YUV에서의 4:2:0로 packing을 해서 video coding을 하게된다.
[inverse 과정]
아래와 동일한 부분
Video encoding하기 위해 YUV 로 packing했으므로 이를 다시 global local coordinate conversion을 해준다. reconstructed된 displacements가 subdivision된 base mesh와 더해져서 deformed mesh(enhancement mesh)가 생성된다.
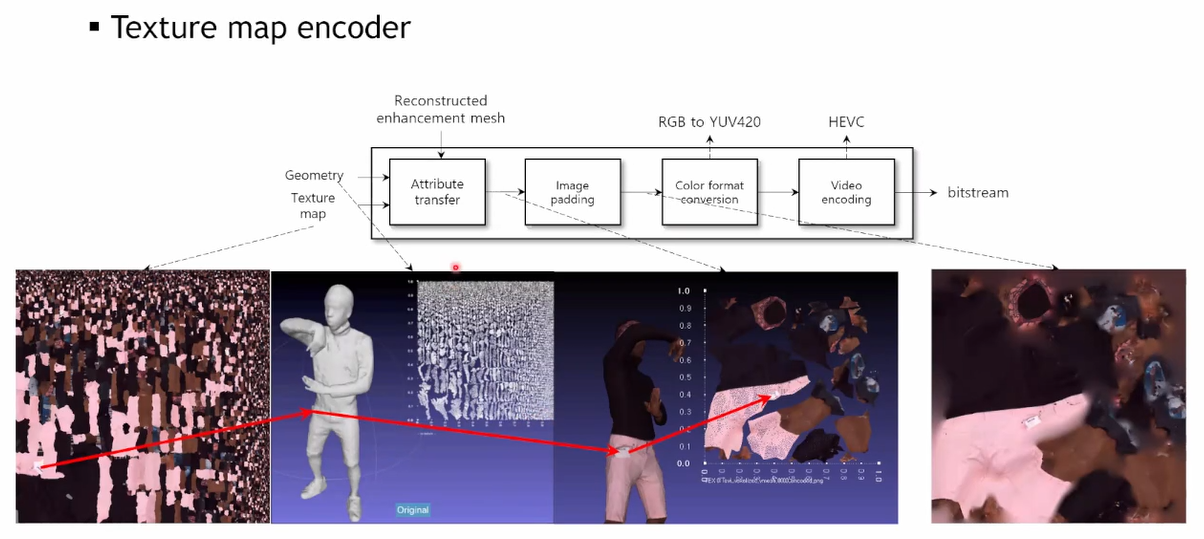
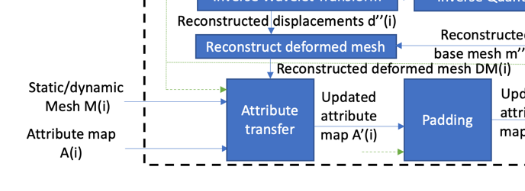
[ attribute transfer ]
Reconstructed deformed mesh와 original texture map(attribute map)을 이용하여 texture map을 mesh에 mapping하는 과정을 보여주고 있다. texture map에 있는 정보를 화살표를 따라 가져온다고 보면 된다. //화살표대로의 관계성이 이미 입증이 되었기 때문에, attribute map에서 바로 화살표 끝단으로 가져오는 아이디어도 있음....이거 우리 코드에 반영됐나???
attribute trasnfer가 끝난 UV domain 즉, texture map을 padding을 한다. texture map에 edge가 많이 생기면 edge 부분은 high frequency를 가져서 video coding efficiency가 떨어지게 되므로 빈 공간을 채우기 위한 padding이 진행된다.
mesh를 이루는 triangle에 대해 trilinear interplation을 하여 빈 부분에 색상을 채워넣는 padding을 진행한다. (push pull algorithm 사용) (계속 down sampling하며 픽셀들이 퍼져나가도록)
이렇게 padding까지 된 RGB image를 YUV 영역으로 conversion하여 encoding을 진행한다.
#### 여기까지 영상 정리 ####
- Deformed Mesh DM(i)
: m’’(i)는 위에서 나왔던 Reconstructed quantized base mesh m’(i)에 inverse quantization를 적용함으로써 얻어진다. reconstructed deformed mesh DM(i)는 m’’(i)를 subdivision하고 reconstructed displacements d’’(i)를 그 vertex에 적용함으로써 얻어진다.
위에서 얻어진 quantized base mesh를 inverse quantization하여 reconstructed base mesh로 가져오고, inverse 과정들 모두 거친 reconstructed displacements도 가져오면, base mesh에 displacements를 더했을 때 reconstructed deformed mesh가 생성된다.
2.2.3 Subdivision scheme
- Subdivision
: Figure 10과 같이 삼각형 하나에 4개의 sub-triangle을 만드는 mid-point subdivision 방법이 쓰인다. 각 edge의 중앙에 vertex가 새로 생기며 재귀적으로 subdivision이 이루어진다. geometry 영역과 attributes 영역의 coordinates가 다르기 때문에, subdivision은 geometry 영역과 texture coordinates(attributes)에 독립적으로 적용된다. //위치 정보와 texture 정보에 대해서 독립적으로 subdivisino된다.
Subdivsion scheme는 edge (v1,v2)의 center에 vertex v12를 새롭게 생성하여 Position Pos(V12)를 계산한다.
동일한 과정이 새롭게 생성될 vertex의 texture coordinates를 계산하는데에도 사용된다. normal vector에 대해서 extra normalizatino step이 적용된다. 각 vertex들에 대한 normal vector을 더한 다음에, 이에 대한 크기(norm)로 나누어 크기를 1로 정규화시켜 v12에 대한 normal vector를 구한다. ??texture coordinates는 normal vectof로 표현되나?
?? preprocessing 과정같은데 왜 여기다 설명하지
2.2.4 Wavelet transform
- Linear Wavelet Transform
: prediction process는 다음과 같이 정의된다. middle point v에 대한 signal과 v1,v2의 평균 signal과의 차이만을 전달한다. //데이터량을 줄이기 위함 //lifting transform에서 residual 남기는 과정 말하는
v*는 vertex v의 인접한 vertex들의 집합을 의미한다. 이 식은 자신의 값과 주변 vertex들의 신호값들의 평균을 취하여 값을 업데이트하느 프로세스를 나타낸다.
//전달된 차이값에 주변 값들 평군내서 더함,,??
- Unifrom Quantizer //Dead zone
: 이러한 Update process는 생략될 수 있다. wavelet coefficients는 dead zone을 가지는 uniform quantizer로 quantization 될 수도 있다.
wavelet transform
2.2.5 Local vs. canonical coordinate system for displacements (좌표계 변환으로 Quantization)
- Canonical vs Local
Displacements field d(i)는 input mesh처럼 cartesian coordinate system에서 정의된다. d(i)를 canonical coordinate system에서 subdivision된 mesh의 각 vertex의 normal vector에 의해 정의된 local coordinate system으로 변경함으로써 최적화할 수 있다.
*** cartesian coordinate system : 직선의 수직 교차를 기준으로 점의 위치를 나타내는 좌표계 *** local coordinate system : 특정 점이나 객체를 중심으로 정의된 좌표계 //vertex들의 normal vector를 기준으로 displacements 좌표계를 최적화하자..!
- Advantage of local coordinate system
: displacements의 tangential components(접선 성분)을 크게 quantization할 수 있다. 실제로 displacements의 normal components는 2개의 tangential components보다 reconstructed mesh quality에 더 큰 영향을 미친다. //그러니 normal 살리고 tangential은 확 줄이는 local 좌표계를 쓰자!
Quantization
2.2.6 Packing wavelet coefficients
- Image Packing
: 아래 과정은 Quantization된 wavelet coeffcients를 Video Encoding하기 위해 2D image로 packing하는 과정이다.
ᄋ Traverse the coefficients from low to high frequency. coefficient들을 낮은 주파수에서 높은 주파수로 쭉 늘여놓는다.
ᄋ For each coefficient, determine the index of NxM the pixel block (e.g., N=M=16) in which it should be stored following a raster order for blocks. 각 coefficient에 대해, raster order를 따라 2D를 이룰 NxM pixel block의 index를 결정한다. //16x16일듯 *** raster order : 왼쪽에서 오른쪽, 위쪽에서 아래쪽
ᄋ The position within the pixel block is computed by using a Morton order [10] to maximize locality. position은 locality(지역성)을 극대화하기 위해 morton order(z-order)를 사용하여 계산된다.
zigzag order나 raster order과 같은 다른 packing schemes도 사용될 수 있다. 인코더는 packing scheme에 bitstream을 명시적으로 전달함으로써 decoder와 scheme에 대한 정보를 공유한다. 이 작업은 patch,patch group,tile, sequenece 단계에서 수행될 수 있다.
//3D로 존재하는 coefficients에 z-order로 indexing하여 2D를 이룰 NxM block을 만들어내는 과정인 듯
//낮은 주파수에서 높은 주파수로 늘여놓는 건 언제하지,,? 3D 상태에서 저걸 어떻게 한다는거지 저게 젤 먼저인데??
2.2.7 Displacement Video Encoding
- Displacement Video Encoding
: 이러한 과정들은 특정 비디오 코딩 기술에서만 사용되는 게 아니라 모델 독립적으로 이루어져있어 다양한 미디오 코딩 기술에 적용될 수 있다.
[무손실 압축] : displacement에 대한 wavelet coefficients를 encoding할 때, quantization은 다른 module에 있기 때문에 무손실로 접근할 수 있다.
[손실 압축] : encoder에 의존하여 coefficient 를 손실 압축하고, original domain이나 transform domain 에서 quantization을 진행하여 데이터의 크기를 더 줄인다.
//Quantization을 다른 module로 뺀다는 게 무슨 말이야??..여기선 여기대로 쭉 처리하고 quantization은 다른데서 해서 video encoding 근처로는 손실 없게 처리하겠다는 말인가??
2.2.8 Attribute Transfer
- inputs
- (no decimated) Original Mesh M(i) //original mesh 정보 - Attribute map A(i) - Reconstructed deformed mesh DM(i) //base mesh기반으로 original과 비슷하게 만들어진 mesh 정보
- Attribute Transfer //속성 정보 전달
: M(i)와 A(i)를 기반으로 DM(i)에 더 잘 맞는 attribute map을 새롭게 생성해내는 것을 목표로 한다. 그 과정은 다음과 같다.
1. attribute map A(i)(n,m)의 각각의 pixel (n,m)에 대해, texture coordinate (u,v)를 계산한다. //좌표 mapping 2. texture 공간에서의 점 P(u,v)가 DM(i)의 triangle에 속하는지 확인한다. 3. [속하지 않으면] P(u,v)가 어떤 triangle에도 속하지 않는다면, padding 알고리즘에서 선택적으로 채워질 수 있는 빈 픽셀로 표시해둔다. //색상은 존재하는데 mesh에는 없는 -> 빈픽셀이라 표시 4.[ 속하면 ] P(u,v)가 vertex (A,B,C)로 정의되는 triangle에 속한다면 - attirbute map의 (n,m) pixel에 "채워진 것"이라고 표시한다. //mesh에 색상이 채워진 것 - P(u,v)의 barycentric coordinates (α, β, γ)를 계산한다. //2D space에서의 triangle position을 사용하여 - P(u,v)와 연관된 3D 좌표를 계산한다. // (α, β, γ)와 3D space에서의 triangle의 3D position을 사용하여 - original mesh의 T'에 위치한 가장 가까운 3D point M'(x',y',z')를 찾는다. - 3D 공간에서의 T'에 따라 M'의 barycentric coordintaes (α', β', γ')를 계산한다. - T’의 세 꼭지점에 연관된 2D 좌표를 사용하여 바리센트릭 좌표(α', β', γ')와 관련된 점 P’(u’, v’)를 계산 - 원본 텍스처 맵을 샘플링하여 속성 값 A’(i)(n’, m’)을 계산하고, 이 속성 값을 속성 맵 A(i)(n, m)의 픽셀 (n, m)에 할당 - 빈 픽셀은 Push-Pull 알고리즘[13]과 sparse linear padding 알고리즘[14]을 결합하여 채운다.
- Padding : push pull 알고리즘을 사용하여 patch들 기준으로 down scaling이후 다시 up scaling할 때 비워져있던 부분들을 interpolation으로 채워가는 것이다.
2.2.9 Colour space conversion and Chroma sub-sampling //색영역 변환, 서브샘플링
- Colour space conversion and Chroma sub-sampling
: 전통적인 2D 이미지/비디오 인코딩과 마찬가지로, colour attribute map을 encoding할 때, 더 좋은 RD performance를 위해 색 영역을 변환하거나 크로마 서브샘플링을 선택적으로 적용할 수 있다.(e.g., RGB 444 to YUV420) //보통은 색보다 밝기가 더 중요해서 색영역 데이터 줄일 때 쓰임
색영역을 변환하거나 서브샘플링을 할 때, 색상에 대한 texture domain에서 표면이 불연속적이라는 것을 고려해야한다. 이를 고려하면 예를들어 동일 patch에 속한 샘플만 고려하고 빈 영역(데이터가 없는 영역)은 제외할 수가 있다.
하지만 제안하는 CfP에서는 HDRtool을 기반으로 해서 빈 영역에 대한 패치 인식 인코딩을 포함하지 않는다.