Paper Review - "Overhead-free region-based JPEG framework for task-driven image compression"
빈그레2023. 10. 24. 16:49
논문 요약
이 논문에서는 딥 뉴럴 네트워크(DNN) 추론을 위해 원격 서버로 스트리밍되거나 장치에 저장되는 캡처 이미지의 양이 증가하는 것에 대해 설명합니다.
***DNN : 많은 은닉층을 가진 신경망을 의미 ***DNN 추론 : training된 지식을 사용하여 새로운 입력 데이터에 대한 예측이나 분류를 수행하는 과정 ***역전파 : 역방향으로 전파하며 가중치 조절
일반적으로 원시 이미지는 리소스 제한을 관리하기 위해 JPEG와 같은 인코딩 알고리즘을 사용하여 압축됩니다.
*** raw image : 이미지 센서로부터 수집된 원시 형태의 이미지 데이터를 나타내며, 컴퓨터에서 처리되지 않은 형태로 저장되어 촬영된 시점에서의 센서 데이터를 보존한다. ***JPEG : 디지털 이미지를 압축하는 데 사용된는 표준화된 이미지 압축 형식 ***resource 제한 : 주로 파일 크기, bandwidth, 저장 공간 등을 의미함.
인간 시각 시스템에 최적화된 표준 JPEG는 DNN 추론 작업에서 정확도가 손실될 수 있다. 표준 JPEG는 이미지의 모든 영역을 동일한 품질 수준으로 압축하지만 일부 영역에는 대상 작업에 대한 가치 있는 정보가 포함되어 있지 않을 수 있습니다.본 논문에서는 대상 기반 JPEG 압축 프레임워크를 제안합니다. -> jpeg은 모든 영역에 대해 동일하게 압축하지만, 반복되는 패턴이 있는 부분이나 큰 의미가 없는 영역에 대해서는 동일한 수준으로 압축이 필요하지 않을 수 있음.
영역 기반 이미지 압축:
관심 영역(ROI)은 목적에 따라 결정되는 이미지의 특정 영역으로, 사람의 시각적 주의나 컴퓨터 비전 작업이 될 수 있습니다. 예를 들어, Simonyan et al. 은 이미지 내의 픽셀들에 대한 예측된 class socre들의 gradient들을 계산하고, 이미지 영역들 및 모델들에 의한 결정들 사이의 의존성을 설명하기 위한 여러 방법들이 제안되어 있습니다. (Colvolutionla Networks for Large-Scale Image Recognition논문 참고//VGGnet)
***ROI : Region of Interest ***일반적으로 이미지나 영상은 모든 부분에 대해 동일한 품질로 압축되지 않는다. 대신, 사용자가 특정 관심영역을 선택하거나 시스템이 중요현 영역을 자동으로 감지하여 해당 부분에 대해 높은 품질의 압축을 적용할 수 있다. 이렇게 함으로써 중요한 부분은 높은 해상도 및 품질을 유지하면서 전체적인 파일 크기는 줄일 수 있게 된다.
??? 중요도가 낮은 부분에 대해 낮은 품질의 압축 방법을 사용하는 것과, 중요도가 높은 부분에 대해 높은 품질의 압축을 적용하는 것은 어떻게 다른가
실험 설정:
QF 맵 생성기 및 예측기는 ImageNet-1K 데이터 세트에서 교육을 받았습니다. 검증 세트의 모든 50,000개의 이미지는 JPEG 프레임워크를 사용하여 처리되었으며, 여기에는 훈련된 QF 맵 생성기 및 예측기가 포함됩니다. 이러한 가공된 영상으로 분류 모델의 성능을 평가하였으며, 교육 및 평가 중 모든 입력 영상의 크기는 224 × 224로 조정되었습니다.
교육 절차:
ImageNet 데이터 세트에 대해 사전 교육된 ResNet50과 VGG16이라는 두 가지 다른 분류 모델을 실험했습니다. BPP 추정기는 ImageNet 데이터 세트로 사전에 교육을 받았습니다. Adam optimizer는 학습률 0.0001의 훈련을 위해 사용되었습니다.
***ResNet (Residual Networks) : Residual block이라는 특별한 종류의 블록을 사용하여 입력 데이터를 바로 더하지 않고, 입력 데이터와 합산된 reisual (잔차) 를 학습하도록 디자인되었다. residual block에서 입력 데이터를 바로 다음 층으로 전달하는 skip connection이 존재한다. 이는 더 깊은 네트워크 학습할 때 gradient 소실 문제를 완화하는데에 도움이 된다.
기준선:
비교를 위해 QF 맵은 Grad-CAM, 바닐라 그래디언트 및 2D 가우스 분포에서 얻은 열지도로 대체되었습니다. 히트맵 성분은 QF로 사용하였으며, 값은 0과 1의 범위로 정규화하였습니다. 승인:
정리
- introduction
이미지 데이터의 폭발적인 증가로 저장되거나 전송되는 데이터의 사이즈를 감소시키는 image compression에 대한 필요성이 커지고 있다.
JPEG,BPG와 같은 traditional한 압축 방법은 HVS(Human Visual System)의 특성을 고려하면서 품질 저하를 최소화함으로써 data rate를 감소시켰다. *** HVS : 인간 시각 체계
그러나 이미지 분류와 같은 딥러닝 기반 컴퓨터 비전 작업의 경우, 기존의 human-centric(인간 중심적) compression methods에 의한 image classification이나 distortion은 상당한 추론 정확도 손실을 가져올 수 있다.
따라서 여러 연구에서, DNN의 추론 작업을 위한 image compression flow를 최적화하기 위해, 다양한 task-driven compression 접근 방식을 제안해왔다. //human-centric <-> task-driven
이전 작업에서 사용된 일반적인 전략은 DNN 기반 압축 프레임워크에 의존하는 것이다. (높은 정확도를 위하여 )
supieror한 compression performance를 가졌지만, 몇몇 DNN-based compression methods는 너무 비싼 computational cost를 가졌다.
게다가, 모든 영역에서 실행되는 작업에 대해 최적화된 딥러닝 모델을 설계하는 것이 불가능하기에 interoperability(상호 운용성)이 떨어진다. 이러한 문제를 완화하기 위해 JPEG과 같은 widely-used & lightweight compression 기술이 시도되었다.
특정 color 나 frequency 에 대한 민감도를 기반으로 standard JPEG의 Quantization table을 재설계하였다. 하지만, standard JPEG 알고리즘과 마찬가지로 알고리즘을 사용하는 경우, 각 region은 prediction에 있어 중요도가 다른데도 불구하고 동일한(uniform) compression level이 적용된다.
post-hoc visual explanation을 활용함으로써 image region의 중요도를 결정할 수는 있지만, 특정 region의 score가 target 정확도 손실에 대해 얼마나 압축해야하는지 절대적으로 나오지는 않는다.
***post-hoc : 모델이 이미 학습되고 예측을 수행한 후에 발생하는 것을 나타낸다. 즉, 모델 학습 ㅣㅇ후에 시행되는 작업이나 분석을 의미한다.
[ROI] : Region of Interest
-> 영역에 대한 세부정보가 필요해 전송 오버헤드 발생 -> 압축 성능을 저하시킬 수 있음
region-adaptive image compression
input마다 다른 compression level 결
region's importance 식별에 대한 학습 신경망을 포함 다른 신경망을 통해 오버헤드 정보 제거 궁극적으로 압축 영상 품질 저하시키지 않으면서 비트율 감소시키기
오버헤드를 무시해버릴 수 있는 접근 방식으로 이미지를 더 낮은 bit rate로 압축 DNN의 더 높은 분류 정확도를 달성하며 재구성된 이미지 생성 가능
2. background jpeg -> block기반 손실 압축 기술
영상의 RGB 값을 휘도(Y)와 크로미낸스(Cb 및 Cr) 값으로 변환한 후 색 정보를 감소시키는 크로마 서브샘플링을 수행
RGB를 변환시킨 YCbCr 색 공간의 각 채널을 8 × 8개의 블록으로 분할하고, 각 블록은 2D 이산 코사인 변환(DCT)에 의해 주파수 성분으로 변환
QF(Quality Factor)로 알려진 정수 스칼라로 양자화 레벨을 지정 ( 표준 JPEG에서는 단일 QF가 각 블록의 다른 의미 정보에 관계없이 모든 블록에 균일 )
양자화를 통해 고주파 성분이 폐기
2.2.1
- saliency map을 생성하는 CNN 훈련 - 각 8*8block을 saliency level에 맞게 압축 - attention network의 output으로 DCT 계수 평활화 -> 압축 품질 향상 ( 낮은 bit rates에서 ) - JPEG 인코딩 과정 전에 CNN으로 이미지 전처리
2.2.2
- JPEG이 표준이었으나 decision error 유발할 수 있음 - DNN에 sensitive한 주파수 성분들 기반으로 quantization table 재설계 - 최적화된 Quantization table 출력을 위해 DNN 훈련
but, 이미지 전 영역에서 균일하게 압축함..... -> 지역별 최적화 필요
2.4
ROI : region of interest .//human visual attention
- ROI 시각화의 측면에서 image region과 decision사이 의존성
- region-based image compression : 이미지 각 영역의 상대적 중요도가 다름 -> 중요한 영역 더 높은 품질로 보존 / 덜 중요한 영역은 더 압축
- region-based compression에 jpeg 사용 : roi 기반 인코딩을 jpeg에 통합할 때 문제!! -> 영역별 압축 레벤 정보를 디코더 측에 추가로 전송해야함
224*224 이미지를 8*8 블록으로 디코딩하려면 784개의 QF 값이 디코더로 전달되어야 함. -> 이미지의 각 블록별 QF가 필요 -> 1~100까지의 정수 QF 값을 나타내려면 7bit가 필요 -> 픽셀당 0.1094비트(BPP) 오버헤드 생김
// 1에서 100까지의 정수 QF 값을 나타내려면 7비트가 필요하므로 픽셀당 0.1094비트(BPP)의 오버헤드가 발생합니다.
전체 영역을 QF 10으로 압축했을 때 ImageNet-1K 데이터 세트[23]에서 이미지의 평균 BPP가 0.4989였던 것을 고려하면, 오버헤드는 총 비트 레이트를 약 22% 증가시킵니다
- salient region을 직사각형으로 제한 -> 해당 직사각형의 두 꼭지점 좌표와 sailency value만을 디코더에 전송 ***salilency value : 얼마나 중요한지 -> overhead 줄어들었음
- 인접한 이미지 region에서 상관관계 높은 부분들에 대해 ROI 정보의 delta encoding사용
**delta coding : 데이터의 차이만을 인코딩하는 방법
연속적인 프레임 간의 차이를 나타내어, 변화가 작은 부분을 효율적으로 표현
- 더 높은 classification accuracy를 위해 jpeg 기반으로 하는 task-driven compression framework 제안 -> blockwise quantization level을 결정하는 light weight DNN 통합 // block 단위로 나눈 image에 대한 최적의 양자화 level 찾기
QF를 추론해버려서 quantization level 정보 보낼 필요 없게 만들기
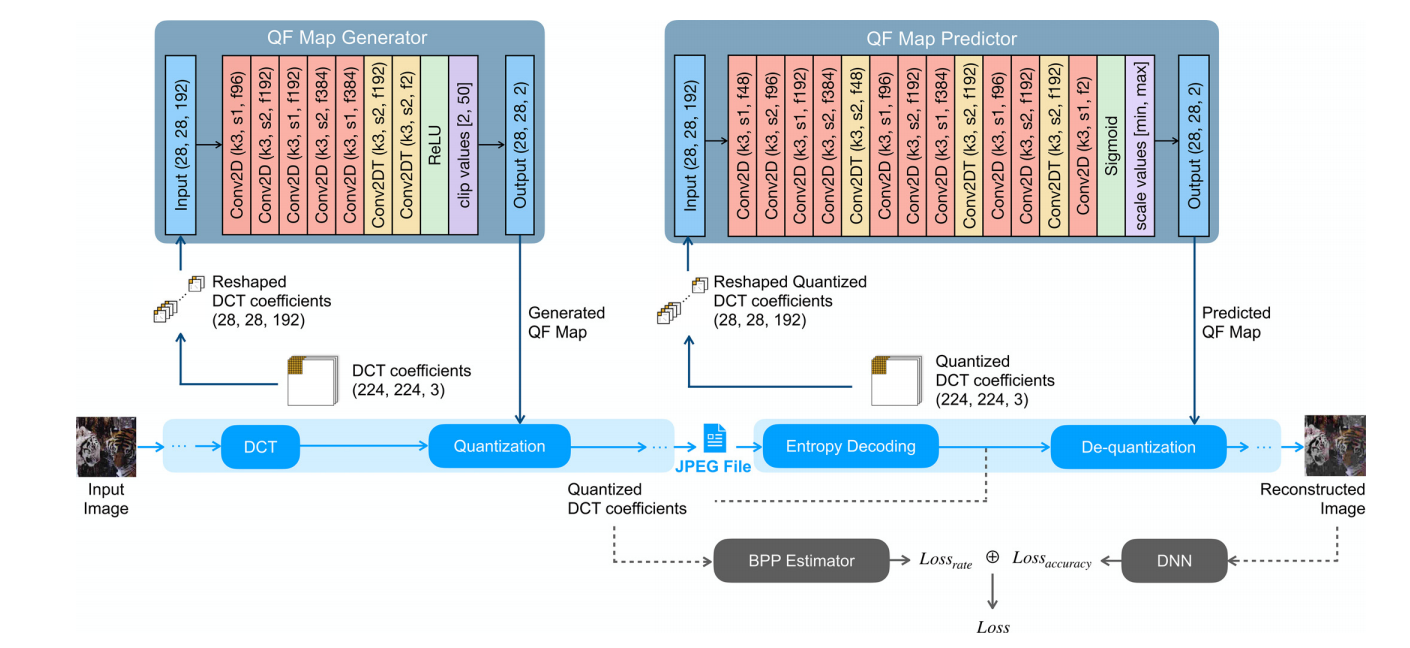
QF map 생성기 : 각 블록(이미지 내의 블록블록)이 얼마나 중요한지에 다라 QF 값 생성. // 객체 식별하는 분류 작업에 얼만큼 중요한 블록인지
Quantized된 DCT 계수로부터 QF map을 예측해서 de Quantization -> encoding된 거 전달할 떄 QF map data 같이 안 줘도 돼서 data 줄어든다.
QF 맵 생성기: 이 구성 요소는 이미지의 각 블록에 대한 최적의 양자화 계수(QF) 값을 생성합니다. QF 값은 이미지의 품질과 압축률을 결정합니다.QF 맵 예측기: 이 구성 요소는 인코딩된 이미지에서 QF 맵을 추론합니다. 이미지의 설명은 다음과 같습니다. 1. 이미지 입력: 이미지는 224x224 크기의 RGB 이미지입니다. 2. DCT 변환: 이미지는 DCT 변환을 사용하여 주파수 영역으로 변환됩니다. DCT 변환은 이미지의 주파수 성분을 분리합니다. 3. QF 맵 생성: QF 맵 생성기는 이미지의 각 블록에 대한 최적의 QF 값을 생성합니다. QF 값은 DCT 계수를 양자화하는 데 사용됩니다. 4. DCT 계수 양자화: QF 값을 사용하여 DCT 계수가 양자화됩니다. 양자화는 DCT 계수의 정확도를 감소시켜 이미지의 압축률을 향상시킵니다. 5. JPEG 인코딩: 양자화된 DCT 계수는 JPEG 인코더를 사용하여 인코딩됩니다. JPEG 인코더는 인코딩된 이미지의 크기를 줄이기 위해 Huffman 코딩을 사용합니다. 6. 인코딩된 이미지 출력: 인코딩된 이미지는 압축된 형태로 출력됩니다. 7. QF 맵 예측: QF 맵 예측기는 인코딩된 이미지에서 QF 맵을 추론합니다. 8. DCT 계수 재구성: 추론된 QF 맵을 사용하여 양자화된 DCT 계수가 재구성됩니다. 9. JPEG 디코딩: 재구성된 DCT 계수는 JPEG 디코더를 사용하여 디코딩됩니다. JPEG 디코더는 Huffman 코딩을 사용하여 디코딩된 이미지의 크기를 늘립니다. 10. 디코딩된 이미지 출력: 디코딩된 이미지는 원본 이미지와 유사한 이미지로 출력됩니다. 이 프레임워크는 기존의 JPEG 압축보다 다음과 같은 이점을 제공합니다. 더 나은 품질: QF 맵 생성기는 이미지의 각 블록의 중요도를 고려하여 QF 값을 생성합니다. 따라서 이미지의 중요한 부분은 더 높은 품질로 유지됩니다.더 나은 압축률: QF 맵 예측기는 인코딩된 이미지에서 QF 맵을 추론합니다. 따라서 QF 맵을 인코딩된 데이터에 포함할 필요가 없습니다. 이는 압축률을 향상시킵니다.